Один из наиболее популярных модулей в Rush Analytics – парсер Яндекс Вордстат, и это не случайно. При сборе семантического ядра необходимо точно знать частотность собранных запросов, чтобы правильно расставить приоритеты по продвижению и избавится от «мусорных» и нулевых запросов. Часто стоит задача пробить несколько десятков тысяч запросов на частотность в Яндексе, но это не совсем простая задача для самописных парсеров Вордстата и десктопных программ, и вот почему:
- Yandex Wordstat имеет хорошую защиту от парсинга, например бан IP-адресов с которых осуществляется парсинг и выбрасывание капчи в ответ на запросы от ботов. Чтобы эффективно собирать данные с Wordstat, нужен эффективный алгоритм подключения IP-адресов и другие хитрости
- Для парсинга большого количества данных с помощью десктопных программ понадобится много IP-адресов (прокси), которые Яндекс с легкостью банит при неоптимальном алгоритме подключения, а прокси – удовольствие недешевое
- Так же для парсинга понадобится автоматическое введение большого количества капчи (например подключение Antigate для этой задачи). Данный фактор, при неоптимальном алгоритме парсинга, может сделать сам парсинг нерентабельным, так как стоимость капчи будет чрезмерно высока
- Большинство десктопных программ не имеют защиты от потери данных при сборе. Так, например, собрав половину данных и потратив на это деньги, при сбое в парсере, вы рискуете не только не получить оставшиеся данные, но и потерять уже собранные
Парсинг Яндекс Вордстат в Rush Analytics
Учитывая все трудности которые могут возникнуть при парсинге Вордстата, мы сделали свой парсер Wordstat максимально быстрым, удобным и устойчивым к максимальному количеству проблем, связанных с парсингом:
- Никаких прокси и капчи! Вам больше не нужно думать о бане ваших прокси или огромном количестве капчи, которую выдает Яндекс. Просто создайте проект, загрузите ключевые слова и ждите готовый файл с результатом
- Высокая скорость парсинга. Наши алгоритмы используют оптимальную схему подключения IP-адресов и другие хитрости, чтобы сделать скорость парсинга феноменально высокой – вы и не заметите, как ваш проект будет выполнен!
- Сохранность данных. Создавая проект в нашем парсере, вы можете быть уверены, что он будет успешно завершен и доступен для скачивания в любое время и из любой точки мира – все данные хранятся в облаке!
- Поддержка всех регионов Яндекса. У многих пользователей есть потребность определять частотность запросов в Яндексе не только по региону «Москва» или «Россия», но и по другим, включая «Украину» и «Беларусь». В Rush Analytics вы сможете определить частотность запросов по любому региону, который поддерживает Яндекс на данный момент.
- Сбор всех частотностей. С помощью нашего парсера вы сможете собрать все частотности: поисковый запрос, «поисковый запрос», «!поисковый!запрос».

- Сбор левой колонки Wordstat. Помимо проверки частотности запросов, доступен сбор ключевых слов из левой колонки Wordstat с настройкой глубины парсинга от одной страницы до сбора всех имеющих в левой колонке страниц.
- Сбор правой колонки Wordstat. Доступен сбор ключевых слов из правой колонки Wordstat.
Если вам нужен скоростной сбор частотностей Яндекс Wordstat – Rush Analytics лучшее решение, особенно если вам нужно собирать большие объемы данных. Для пользователей с потребностью сбора боле 100 000 запросов в месяц предусмотрены индивидуальные условия, просто напишите в нашу поддержку на
Здравствуйте, уважаемые читатели!
Появилась идея объединить все статьи, касающиеся темы частотности поисковых запросов. И вот я спешу ее воплотить.
Сегодня мы поговорим об анализе частотности поисковых запросов, объединив все знания, накопленные в предыдущих текстах.
Частотность запросов
Прежде всего, снова определимся, как мы будем группировать запросы. Уже ни для кого не секрет, что выделяются низкочастотники (НЧ), среднечастотники (СЧ) и высокочастотники (ВЧ). Но как определить, к какой группе отнести запрос? Ранее я предложил такую схему:
- НЧ – до 700 запросов в месяц;
- СЧ – до 2000 запросов в месяц;
- ВЧ – все остальные.
Эта схема и сейчас справедлива, но применима она для сео-тематики.
В действительности же большинство сеошников руководствуются следующей схемой:
- до 1000 – низкочастотные;
- 1 – 10 тыс. – среднечастотники;
- свыше 10 тыс. – высокочастотники.
Эта формула также верна, но она считается общей. Если же вы работаете в конкурентных тематиках, где пробиться в ТОП поисковиков крайне сложно, то эти цифры снижаются.
Теперь вы понимаете, что частотность лучше определять в зависимости от того, к какой тематике принадлежит ваш ресурс.
НЧ, СЧ и ВЧ
Я думаю, не стоит подробно описывать каждый тип запросов, его особенности и нюансы. Все это уже было достаточно подробно изложено в предыдущих статьях, вам просто нужно их прочитать:
Эта тема также неоднократно поднималась в предыдущих статьях (например, в статье ), но, как говорится, повторение – мать учения.

Итак, есть три сервиса, которые подходят для анализа частотности запросов:
- Гугл.Адвордс
- Рамблер.Адстат
Самый точный – Яндекс.Вордстат, т.к. он охватывает более 50% русскоязычной аудитории (через поисковики Яндекс, Мейл и т.д.), соответственно и цифры здесь самые близкие к истине.
На втором месте – Адвордс от Гугла. Область охвата рунета – около 30%, поэтому точность определения запросов тут ниже. Но все же этот сервис не стоит сбрасывать со счетов.
Хуже всего определяет частотность запросов Рамблер.Адстат, статистика которого покрывает около 10% рунета. Про Гугл.Адвордс и Рамблер.Адстат читайте в статье « ». Про вордстат поговорим подробнее.
Вордстат
Перейти на этот сервис можно по этой ссылке .
Введя поисковый запрос, вы получите картину его частотности. Не забывайте использовать операторы вордстата:
- Если введен в окошко запрос (окна пвх), то будет посчитано, сколько раз был вообще набран этот запрос в яндексе (окна пвх, стоимость окн пвх, купить окна пвх, окна пвх в Москве и т.д.)
- Если запрос введен в кавычках («окна пвх»), то будет посчитано, сколько раз использовался этот запрос и его словоформы (окна пвх, окон пвх, окнами пвх, окнам пвх и т.д.)
- Если ввести запрос в кавычках и с восклицательным знаком перед каждым словом («!окна!пвх»), то будет посчитано, сколько раз вводился конкретно данный запрос.
Поэтому если вам нужно знать точное количество запросов, то используйте кавычки и восклицательные знаки.

Определяя частотность, не забывайте, что низкочастотный запрос не всегда бывает низко конкурентным, а высокочастотный – высоко конкурентным. Поэтому будьте внимательны, старайтесь определять и частотность и конкурентность запроса.
Перед тем, как что-то делать в интернете: создавать сайт, настраивать рекламную компанию, писать статью или книгу, надо посмотреть, что вообще ищут люди, чем интересуются, что вводят в поисковой строке.
Поисковые запросы (ключевые фразы и слова) чаще всего собирают в двух случаях:
- Перед созданием сайта. В этом случае нужно собрать максимум ключевых слов, чтобы охватить всю вашу сферу. После сбора, поисковые запросы анализируются и на основании этого принимается решение о структуре сайта.
- Для настройки контекстной рекламы. Для рекламы выбирают не все, а только слова, по которым можно определить интерес к товару или услуге, желательно активный интерес выраженный словами «купить», «цена», «заказать» и т.п.
Если вы собираетесь настраивать контекстную рекламу, то .
А ниже мы рассмотрим, как собрать статистику поисковых запросов в популярных поисковых системах, а так же небольшие секреты, как это сделать лучше.
Как посмотреть статистику запросов Яндекс
У поисковой системы Яндекс есть специальный сервис «Подбор слов», находящийся по адресу http://wordstat.yandex.ru/ . Пользоваться им очень просто: вводим любые слова и обычно, кроме статистики по этим словам, также видим что искали вместе с этими словами.
Очень важно понимать, что статистика по более коротким запросам, включает в себя статистику всех подробных запросов с этими словами. Например, на скриншоте запрос «статистика запросов» включает в себя запрос «статистика запросов яндекс» и все остальные запросы ниже.
В правой колонке отображаются запросы, которые искали люди, искавшие введенный вами запрос. Откуда берется эта информация? Это запросы, которые были введены до вашего запроса или сразу после него.
Чтобы посмотреть точное количество запросов по фразе, надо ввести ее в кавычках «фраза». Так, конкретно запрос «статистика запросов» искали 5047 раз.

Как посмотреть статистику поисковых запросов Google
С недавних пор для России стал доступен инструмент Гугл Тренды, он находится по адресу http://www.google.com/trends/ . Он выводит популярные в последнее время поисковые запросы. Вы можете ввести любой свой запрос, чтобы оценить его популярность.
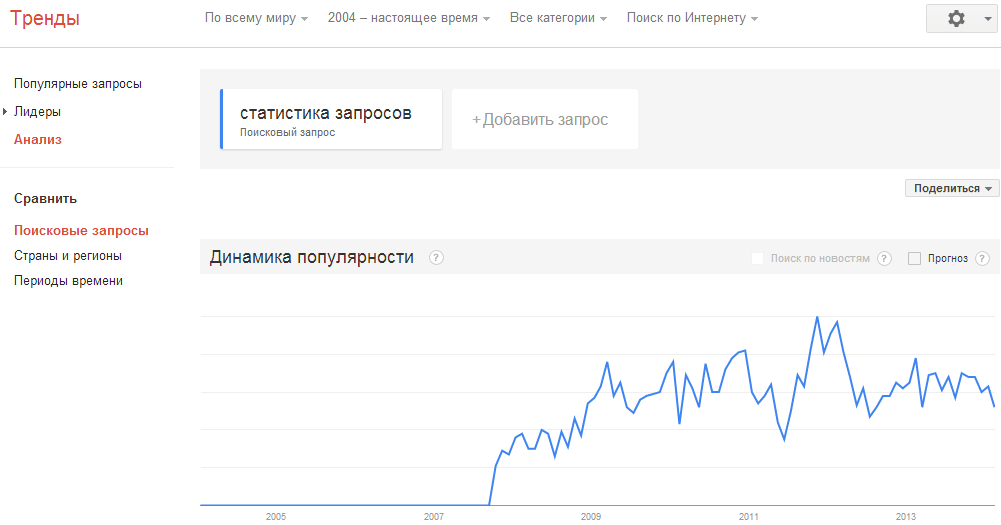
Кроме частоты запросов, Google покажет популярность по регионам и схожие запросы.
Второй способ посмотреть частоту поисковых запросов Гугл — это использовать сервис для рекламодателей adwords.google.ru. Для этого нужно зарегистрироваться как рекламодатель. В меню «инструменты» нужно выбрать «Планировщик ключевых слов» и дальше «Получить статистику запросов».

В планировщике, кроме статистики, вы узнаете уровень конкуренции рекламодателей по этому запросу и даже примерную стоимость клика, если решите тоже рекламироваться. К слову, стоимость обычно завышена.
Статистика поисковых запросов Mail.ru
Майл.ру обновил инструмент показывающий статистику поисковых запросов http://webmaster.mail.ru/querystat . Главная фишка сервиса — это распределение запросов по полу и возрасту.
Можно предположить, что сервис подбора слов Яндекса также учитывает запросы из Mail, т.к. в данный момент поисковая система Mail.ru показывает рекламу Яндекса, а сервис в основном рассчитан на рекламодателей. А раньше кстати, в Mail.ru показывалась реклама Google.
Кроме того, можно пользоваться такой хитростью. Примерное распределение аудитории между поисковиками такое: Яндекс — 60%, Гугл — 30%, Mail — 10%. Конечно, в зависимости от аудитории, соотношение может меняться. (Например, программисты могут отдавать предпочтение Google.)
Тогда можно посмотреть статистику в Яндекс и делить на 6. Получаем приблизительное количество поисковых запросов в Mail.ru
Кстати, точное распределение аудитории между поисковиками на Февраль 2014 года можно увидеть на скриншоте снизу:

Статистика запросов Rambler
Из графика выше уже можно заметить, что поисковая система Рамблер охватывает всего 1% аудитории интернета. Но тем не менее, у них есть свой сервис статистики ключевых слов. Он находится по адресу: http://adstat.rambler.ru/wrds/

Принцип такой же, как и в остальных сервисах.
Поисковой системой Бинг пользуется еще меньше наших соотечественников. А чтобы посмотреть статистику ключевых слов, придется зарегистрироваться как рекламодатель и разбираться в инструкциях на английском языке.
Сделать это можно по адресу bingads.microsoft.com, а статистику запросов можно будет посмотреть на этапе создания рекламной компании:

Статистика запросов Yahoo
В этой системе как и в предыдущей, вам нужно зарегистрироваться как рекламодатель. Смотреть статистику поисковых запросов надо здесь http://advertising.yahoo.com/
Как посмотреть поисковые запросы Youtube
Youtube тоже имеет свою статистику поисковых запросов, который называется «Инструмент подсказки ключевых слов». В основном он предназначен для рекламодателей, но ведь его можно использовать, чтобы прописывать у своего видео подходящие ключевые слова.
И выглядит примерно вот так:
Итог.
Мы рассмотрели все популярные системы подбора поисковых запросов. Надеюсь, этот обзор пригодится вам для написания статей, создания сайтов или настройки рекламы. Если у вас остались вопросы — задавайте их в комментариях.
Предлагаю бюджетное продвижение сайта за 15 000 руб/месяц.. Никакого чуда, если конкуренция высокая — я не возьмусь продвигать такой сайт.
Здравствуйте, уважаемые читатели блога сайт! На очереди очередной инструмент по подбору семантического ядра сайта, причем весьма качественный и не уступающий программным аналогам. Его нам предлагает онлайн сервис Topvisor.ru , который является на данный момент, пожалуй, самым прогрессирующим на просторах рунета.
Прошлая публикация была посвящена полному , ну а сегодня во всех подробностях рассмотрим сбор семантического ядра и оценим возможности данного сервиса в этом плане. Вы увидите, насколько удобно и просто работать в интерфейсе, где все продумано до мелочей.
Ведь время всегда было и остается на вес золота, а уж в нашу эпоху и подавно. Поэтому за сравнительно небольшие деньги вы получаете очень качественный результат. Особенно, если учесть, что в Топвизоре реализована возможность не просто собрать , попутно определив цену за клик и частотность запросов , но и сразу сгруппировать ключевые слова под продвижение разделов или даже отдельных статей вашего сайта.
Поиск ключевых слов в Яндексе, Google и других ПС
А теперь переходим к практике, а именно к составлению СЯ. Надо сказать, что Topvisor предоставляет для этого абсолютно, подчеркиваю, абсолютно, все инструменты и помогает подобрать ключевые слова для сайта автоматически в онлайн режиме. Вначале из верхнего меню выбираем нужный нам проект и переходим во вкладку «Ядро» , где находится серый прямоугольник, в центре которого расположен большой «+»:

После нажатия на этот плюс образуется новая группа (блок), которой можно присвоить нужное название и в состав которой можно различными способами добавлять ключевики. Но об этой возможности мы поговорим чуть позже, так сказать, в процессе.
Напомню сразу, что можно импортировать необходимые запросы для семантического ядра, которое вы будете составлять для уже действующего либо будущего вебпроекта. С этой целью достаточно нажать на соответствующую кнопку:

Выплывет отдельное окно, в котором можно ввести необходимые ключевики двумя способами: просто вписать их по одному в строку вручную (или скопировать в буфер обмена и вставить) либо скачать файл в формате CSV или TXT:

Сначала же для примера введем ПЗ (можно сразу несколько) в форму, которую можно активировать, нажав на кнопку поиска ключевиков:

Итак, попросим Топвизор подобрать ключевые слова Яндекс Директ, которые связаны с заданной фразой, отметив галочкой «С этим искали». Здесь необходимо сделать отступление и напомнить, как происходит нужных словосочетаний, которые будут использоваться затем в качестве ключевиков для продвижения отдельной статьи или сайта в целом.
Дело в том, что в левой части Вордстата будут находится словосочетания, которые являются производными от введенной вами фразы или слова. В случае, если ключ достаточно популярен, может образоваться правая колонка, в которой будут представлены так называемые ассоциативные запросы, вводимые пользователями в течении этой же самой поисковой сессии:

В ходе парсинга ключевых слов Яндекс автоматически образует несколько групп для каждого введенного КС, где будет происходить имитация известных игр "Тетрис" или "Змейка". Процесс займет всего лишь несколько минут и по его окончании станет видимым результат:

Здесь представлены перечни основных и сопутствующих (с этим искали) слов. Для некоторых уже показана частотность в Яндексе (правая колонка) и стоимость клика рекламы в Директе (левая колонка). Вообще для получения этих данных в полном объеме требуется активировать отдельную операцию, чем мы и займемся чуть ниже. Однако, Топвизор любезно предоставляет сразу часть информации, которая была уже оплачена другими юзерами этого сервиса.
Точно таким же образом система находит ключевые слова Гугл из статистики Adwords (напомню, что существует ), Webmaster Mail, Webmaster Bing. Правда, для Бинга нужно еще указать период, за который вы желаете получить данные (по умолчанию это последний месяц):

Ну и добиваем сбор КС из поисковых подсказок:

Теперь встает резонный вопрос: а что же такое эти самые поисковые подсказки? Дело в том, что когда пользователь начинает вводить словосочетание в поисковое поле, система предлагает ниже строки поиска сразу несколько вариантов, которые наиболее часто использовались другими юзерами. Рассмотрим все это на примере Яндекса. Откроем страницу поиска и введем запрос из нашего примера:

Все появившиеся внизу словосочетания являются подсказками первого уровня . Ежели взять из этого списка одну из фраз, то при ее вводе появится уже перечень подсказок второго уровня :

И так далее. Таких уровней может быть очень много. Естественно, не все ключи имеют подобные "хвосты", многое зависит от популярности вводимой фразы. Topvisor предлагает три уровня поисковых подсказок, что вполне может обогатить состав семантического ядра. Но продолжим. После парсинга всех возможных источников будут сформированы отдельные группы ключевиков.

Самое замечательное в том, что повторяющиеся слова и словосочетания, полученные из разных мест, система отсеивает автоматически, поэтому исключена любая путаница. Чтобы дополнить список ключевых слов для семантического ядра, Топвизор предлагает еще одну возможность для тех, кто уже имеет сайт со страницами, оптимизированными под определенные ключевые слова, по которым существуют переходы пользователей.
Жмем на кнопку с изображением магнита, которая инициирует сбор статистики из Я.Метрики и Google Analytics (о том, как интегрировать данные из этих сервисов, написано в статье с обзором всего функционала Топвизора, на которую вы можете перейти по ссылке в самом начале публикации):

После завершения процесса образуется новый перечень ключей, которые будут соответствовать уже существующим статьям с реальными визитами и к которым можно будет добавить еще не учтенные словосочетания, которые найдутся с помощью Топвизора.
Массовая проверка частотности запросов онлайн и определение цены клика в Директе и Adwords
Итак, мы получили целую кучу всевозможных фраз для ядра из различных источников с помощью функции подбора ключевых слов онлайн. Теперь настало время систематизировать все это богатство, удалив бесперспективные фразы, включая пустышки, по которым продвигать страницы будет нерентабельно и затратно. С этой целью для начала необходимо проверить частотность запросов в Яндексе (ну и до кучи в Гугле, это тоже может оказаться полезным). Жмем на соответствующую кнопку во вкладке «Ядро» и выбираем источник:

Здесь для получения необходимой нам информации требуется указать тип соответствия: "фразовое" или "точное", а также пропустить уже проверенную частотность, проставив галочку напротив соответствующей опции. Тем самым мы не платим лишних денег за уже полученные ранее результаты. Запускаем процесс, ход которого обозначен бегущими по поверхности кнопки полосами:

По окончании сего действа Топвизор попросит вас обновить страницу, после чего можете лицезреть результирующую картинку:

Если вы обнаружили, что по-прежнему не по всем ключевикам отображается частотность запросов Яндекс Директ , то нужно выбрать в верхней панели с помощью переключателя опцию «Фразовая», поскольку здесь по умолчанию выдается обычно «Базовая».
Моя сущность перфекциониста не позволяет оставить возможные белые пятна, поэтому придется поподробнее затронуть нюансы частотности и стоимости за клик. Тем более, что эта информация напрямую поспособствует пониманию того, какие ПЗ следует принять во внимание, а какие отбросить.
В принципе, статистика ПЗ Я.Директа подходит как рекламодателям, для которых она и создана, так и вебмастерам, поэтому мы можем ее использовать в своих изысканиях. В предыдущих статьях я уже касался операторов для подбора слов , которые помогают получить корректную частотность и исключить пустышки.
Если для рекламодателей очень важно использовать все операторы в зависимости от типа ключей, то для вебмастеров, особенно имеющих стандартный информационный ресурс типа моего, достаточно двух, а именно кавычек («""»), в которые заключается слово или фраза, и восклицательного знака («!»), проставляемого перед каждым словом в словосочетании.
Все-таки, наверное, от примеров не уйти, чтобы уж совсем все было ОК. Итак, если в том же Вордстате ввести ключевую фразу, то можно получить частотности с различными вариациями.
1. Обычная - в этом случае вы получаете набор словосочетаний, включающих данную фразу. Но действительная частота может быть намного меньше, поэтому такой вариант является чисто информативным:

2. Фразовая - тут ключ заносится в кавычки и полученные данные будут содержать данное словосочетание во всех формах (различных числах, падежах и т.д.):

Именно этот вид я обычно применяю при продвижении статей, поскольку в основном оптимизирую материал сразу под несколько ключевиков и очень сложно использовать их всех в строгой вариации.
3. Точная - здесь надо добавить восклицательный знак перед каждым словом. В итоге будет выявлена частотность с прямым вхождением:

Последние два типа и применяются при составлении ядра. Тут тяжело дать рекомендации, какой из них эффективней, многое зависит от направленности и тематики сайта. Хотя, если у вас информативные страницы с небольшими текстами, продвигаемые под один-два ключевика, то, наверное, лучше выбрать точную частотность.
Теперь попробуем узнать стоимость клика в Яндекс Директ. Существует три вида расценок контекстной рекламы в зависимости от места расположения объявлений: «спецразмещение», «1-ое место» и «гарантия» . Попытаемся проанализировать, что они все означают. Конечно, напрямую эта информация предназначена в первую очередь рекламодателям.
Дело в том, что при составлении кампании в Директе назначаются цены за размещение рекламных объявлений в том числе на странице поиска Яндекса. Наверное, наглядно места расположения рекламы демонстрирует вот этот скриншот:

То есть спецразмещение подразумевает нахождение рекламы вверху страницы, а в самом верху будет расположено объявление, соответствующее 1-му месту. Естественно, что за размещение на таких выгодных позициях рекламодатель должен выложить кругленькую сумму и цена за клик будет достаточно высокой.
А теперь представьте, что вы продвигаете статью под конкретный запрос, где стоимость клика достаточно высока. Даже если этот материал попадет в топ выдачи, не факт, что эта страница получит достаточное количество посетителей, поскольку по этому же ключевику присутствует целый блок рекламных объявлений, которые расположены выше списка результатов поиска.
Тем более, что в недавнем прошлом Яндекс убрал нумерацию страниц, тем самым визуально пользователю стало труднее воспринимать отличия собственно содержания поиска от рекламы. Ну и последний вид цены за клик - «гарантия». В этом случае рекламные блоки находятся в самом низу страницы после результатов поиска, поэтому в этом случае цена будет гораздо ниже.
На основании выше сказанного резюмирую, что для анализа ПЗ лучше всего использовать статистику по типу спецразмещения. И после сбора всех данных следует отсеять те ключи, по которым стоимость клика слишком высока, так как продвижение по ним будет неэффективным. Этим мы займемся чуть позже. Однако, надо учитывать следующее.
Ведь наверняка многие уважающие себя вебмастера участвуют в и размещают на своем ресурсе , что является одним из , приносящим порой немалый доход. Но контекст на странице, естественно, завязан на ее содержании. Значит, на тех ключах из семантического ядра, под которые заточена публикация.
Поэтому использовать запросы с низкой ценой клика в этом смысле тоже невыгодно . Нужна золотая середина. Постарайтесь выбирать те ключевики, которые, с одной стороны, способны вывести страницу в ТОП, а с другой, будут приносить вам доход от РСЯ. Но это, так сказать, моя правда, ведь могут быть другие варианты, не правда ли?
Точно также совершается парсинг и для Гугла, правда здесь результаты частоты ключевиков и стоимости кликов предлагаются в единственном варианте:

Последним источником, по которому можно парсить данные, является Webmaster Mail. Хотя, в этом случае вы получите информацию только по частотности запросов. Думаю, до этого момента вам все понятно, по крайней мере, я старался донести всю нужную информацию в доступной форме.
Функция фильтрации в интерфейсе Топвизора
Итак, мы создали с помощью системы несколько списков необходимых нам словосочетаний для ядра. Теперь необходимо отсеять "пустышки", то есть ключи с очень маленькой частотностью (например, менее 10), поскольку продвигаться под них только время терять. Никакого сколь-нибудь заметного трафика они не дадут, а драгоценное время отнимут. Жмем кнопку фильтрации и выбираем ее вид из выпадающего меню:

В результате при таких настройках запросы с установленной минимальной частотой упадут в отдельный список, предложенный Топвизором. Возможно, впоследствии кое-какие из этих ключей могут пригодится (например, возрастет частотность, что иногда случается). Далее таким же способом можно отсеять пустые блоки, не имеющие ни одного ключевика:

Точно также посредством фильтра можно отсортировать ключевики по позициям и полностью очистить ядро, если вам это вдруг понадобиться.
Кластеризация запросов семантического ядра сайта
Вот мы и подошли к решающему этапу, который, пожалуй, является основным при составлении семядра вебсайта. Именно эта функция Топвизора позволяет произвести группировку ключевых слов таким образом, чтобы обеспечить наиболее эффективную структуру вашего проекта для дальнейшего продвижения.
Кластеризация ядра дает возможность распределить все запросы так, чтобы они составляли готовые списки не только для каждого раздела вашего вебсайта, но и для любой из страниц. Если вы запланируете написать статью на определенную тему, то список ключевых слов для нее будет уже практически готов. Конгениально, не правда ли?
Но на чем же основывается система и какими соображениями она руководствуется? А происходит это следующим образом. Сервис исследует содержание ТОП-10 соответствующей поисковой машины и находит совпадения групп ПЗ всех сайтов, которые находятся на верхних позициях.
Ежели таких совпадений несколько, то ключевики объединяются в блоки, названия которых определяет самый высокий по частотности запрос. Те словосочетания, по которым не найдено ни одного совпадения, попадают в отдельный список "Запросы без связей".
Все это довольно логично. Ведь если в ТОП-10 попали страницы сайтов с таким набором ключей, значит, поисковые системы благосклонно к этому относятся, и есть смысл последовать их примеру. В общем, группировка это операция, которая придает законченность семантическому ядру. Вот так активируется процесс кластеризации:

Обратите внимание, что существует возможность выбора степени группировки. Эта величина определяется количеством документов с одинаковым набором запросов, по которым будет производится кластеризация. Вероятность того, что будут совпадения, скажем, по двум страницам, попавшим на первые места, гораздо выше, чем по восьми-девяти.
Таким образом, чем меньше степень, тем более объемными по содержанию будут блоки и их количество будет меньше. Однако, совпадения по одному-двум запросам тоже недостаточно, поэтому по умолчанию Топвизор предлагает степень группировки 3.
Вы вольны выбрать для себя любую степень, только обязательно учитывайте выше предложенные рассуждения. Лично я оставляю настройки по умолчанию, так как считаю их наиболее эффективными для стандартного информационного ресурса. Но, как говорится, возможны варианты.
Нужно заметить, что процесс кластеризации ядра длится недолго, для тысячи ключей, к примеру, он не занимает более 5 минут. После окончания распределения словосочетаний по умолчанию полученные группы будут отключены (кружок красного цвета слева от названия блока), то есть съем позиций по ним производится не будет:

Если нажать на красный кружок левой кнопкой мышки, то можно включить нужные группы для определения позиций. В этом случае он поменяет цвет на зеленый. Точно также возможна обратная операция. Включить/отключить все блоки возможно с помощью переключателя в правом верхнем углу:

Технические возможности интерфейса Топвизора
Итак, все действия по составлению семантического ядра описаны и разобраны. Теперь посмотрим, какие возможности предоставляет нам сервис для наиболее удобной работы. Естественно, что после получения полноценного ядра у вас образуется достаточно много групп. Чтобы комфортно ими управлять, можно выделить нужные вам на этот момент и пометить их галочками, нажав на кнопку с изображением глаза:

В итоге на экране появятся лишь те, которые вы выберите, остальные будут просто скрыты из области видимости. Также существует возможность самыми разнообразными способами редактировать состав групп и перемещать сами блоки и отдельные ключевики в интерфейсе.
Вы добавляете сколь угодное число новых групп, каждый раз нажимая на большой плюс в центре серого прямоугольника. Тут же вы сможете определить названия блоков (редактируя или полностью изменяя их):

Идем дальше. Любой созданный список можно полностью удалить, нажав на традиционный значок с изображением корзины, распределить все словосочетания по алфавиту, по возрастанию или убыванию частотности или цены за клик (две направленные в противоположные стороны стрелки):

Кроме того, если ввести ключевую фразу в нижнюю графу, которая присутствует в каждом блоке, и нажать на плюсик, то данное словосочетание будет немедленно добавлено в группу. Ежели в ней собралось достаточно большое количество ключевых фраз (более ста), то она будет разбита на несколько страниц. Номер страницы можно выбирать из выпадающего меню в правом верхнем углу блока.
Обратимся еще раз к верхнему меню. Иконка с корзиной дает возможность посмотреть, какие последние поисковые запросы были удалены (в количестве 20 штук) и при необходимости восстановить какой-то из них, щелкнув по нему левой кнопкой мыши:

В дополнение к выше сказанному данный сервис предлагает кроме отображения групп блоками еще и табличный режим , который, кстати, станет постоянным, если число ключевиков перевалит за 5000 (в этом случае вывод блоков станет невозможным). Переключение между двумя способами происходит с помощью двух первых кнопок верхней панели:

В этом виде с таблицами можно производить практически те же действия: удалять отдельные слова или фразы, блоки, изменять названия групп, добавлять новые. Акцентирую внимание на том, что режим таблиц удобнее в плане наличия всех главных показателей.
Сюда входят различные виды частотности и цены за клик, причем их, как и в блочном режиме, можно упорядочить как по возрастанию, так и по убыванию значений. Вдобавок даны статистические данные по трафику и позициям, если вы уже осуществляли проверку для данного списка ключевиков.
Щелкнув по ссылке "выделить видимые" , вы инициируете выделение находящихся в поле зрения ключевых слов. Одновременно в самом низу вылезет желтая панелька, которая позволит произвести с выделенными словами различные действия: переместить во вновь созданную или уже имеющуюся группу, назначить целевую страницу или удалить.
Количество имеющихся в зоне видимости ПЗ можно регулировать четырьмя кнопками, которые добавляют нужное их число (+10, +50, +100 и +500). Ну и конечно все эти данные можно легко скачать, нажав на соответствующую кнопку «Экспорт запросов»:

Есть возможность указать, какие данные вы желаете экспортировать в файле формата TXT или CSV. Ежели скачиваете с расширением CSV, то в дальнейшем документ можно открыть в программе Excel либо загрузить в интерфейс Гугл Таблиц, куда можно попасть в том числе через свою , если, конечно, вы уже имеете там свой аккаунт. Вот как выглядит, например, скачанный мною документ из Топвизора в Google Sheets:

Для наглядности я некоторым образом отредактировал эту таблицу. На этом, пожалуй, сегодня все. Надеюсь, вы получили полное представление, как составить семантическое ядро онлайн в полном объеме. Еще раз отсылаю вас к началу статьи, где дана ссылка на подробный обзор Топвизора, где вы сможете ознакомиться с ценами на те или иные услуги, чтобы иметь представление и об этом аспекте. Удачного продвижения.
Есть несколько сервисов, позволяющих спрогнозировать частотность поисковых запросов , но большинство специалистов использует сервис от Яндекса - Яндекс Вордстат.
Отступление
У Яндекса существенная доля рынка (большая выборка данных) и удобный инструмент для анализа (Яндекс Вордстат). В инструменте от Mail вы можете получить более расширенные данные по каждому ключевому запросу, но на гораздо меньшей выборке данных. Сервис Яндекс Вордстат создавался в первую очередь для Яндекс Директа, но является очень полезным для seo-специалистов.
3 вида частотности запроса в Яндекс Вордстат
Ежедневно seo специалисты в своей работе используют 3 вида частотности. Вам необходимо уловить разницу и научиться правильно интерпретировать информацию, понять ее ценность.
Общая частость - это прогнозируемое количество показов в месяц введенной фразы с любым другими словами в любом падеже/склонение/числе и т.п. То есть, если вы введете запрос [доставка пиццы], то получите количество показов в месяц таких запросов, как: [доставка пиццы], [доставка пиццы круглосуточно], [недорогая доставка пиццы в Санкт-Петербурге в 3 часа ночи], [пицца ахтынзан доставка в Екатеринбург] и т.п.
Яндекс:Цифры рядом с каждым запросом в результатах подбора слов дают предварительный прогноз числа показов в месяц, которое вы получите, выбрав этот запрос в качестве ключевого слова. Так, цифра рядом со словом «телефон» обозначает число показов по всем запросам со словом «телефон»: «купить телефон», «сотовый телефон», «купить сотовый телефон», «купить новый сотовый телефон в крапинку» и т.п.
То есть Яндекс говорит нам, что слово «пицца» и любые словосочетания со словом «пицца» наберут 2 242 196 раз в месяц, а фразу «доставка пиццы» и все словосочетания с фразой «доставка пиццы» наберут 240 705 раз в месяц. С помощью этой информации можно найти интересные кластеры запросов, которые набирают пользователи и проанализировать потребности потенциальных клиентов. Например, здесь явно видно, что только 10% пользователей, которые искали что-либо связанное с пиццей, ищут ее доставку.
Часть пользователей хотят получать пиццу круглосуточно, а для другой части пользователей очень важно, чтобы пиццу привезли быстро. Это весьма ценная информация для вашего бизнеса, поэтому экспериментируйте и ищите интересные потребности в запросах.

2. Точная частотность запросов
Точная частость - это прогнозируемое количество показов в месяц введенной фразы без каких-либо других слов , но в любом падеже/склонение/числе и т.п. То есть, если вы введете запрос «доставка пиццы», то получите количество показов в месяц таких запросов, как: [доставка пицца], [пицца доставка], [доставка пицц] и т.п.
Чтобы получить точную частотность запроса, весь запрос необходимо взять в кавычки:

Точная частотность поможет найти ключевые запросы, которые реально набирают пользователи. Также обратите внимание, что только 6% пользователей , которые ищут что-либо с доставкой пиццы ограничиваются запросом [доставка пиццы], а 94% пользователей дополняют (конкретизируют) свой запрос.
3. Супер точная частотность запросов
Супер точная частость - это прогнозируемое количество показов в месяц введенной фразы без каких-либо других слов и в указанном падеже/склонение/числе и т.п. То есть, если вы введете запрос «!доставка!пиццы», то получите количество показов в месяц запроса [доставка пиццы].
Чтобы получить точную частотность запроса, весь запрос необходимо взять в кавычки и перед каждым словом поставить восклицательный знак:

Супер точная частотность позволяет выявить в каком падеже, числе и склонение люди набирают определенные запросы.
Предлоги в Яндексе
В вордстате не учитываются предлоги, когда вы анализируете общую частотность. Если вам нужно посмотреть ключевой запрос с предлогом, то перед предлогом необходимо поставить «+».
Прочувствуйте разницу:
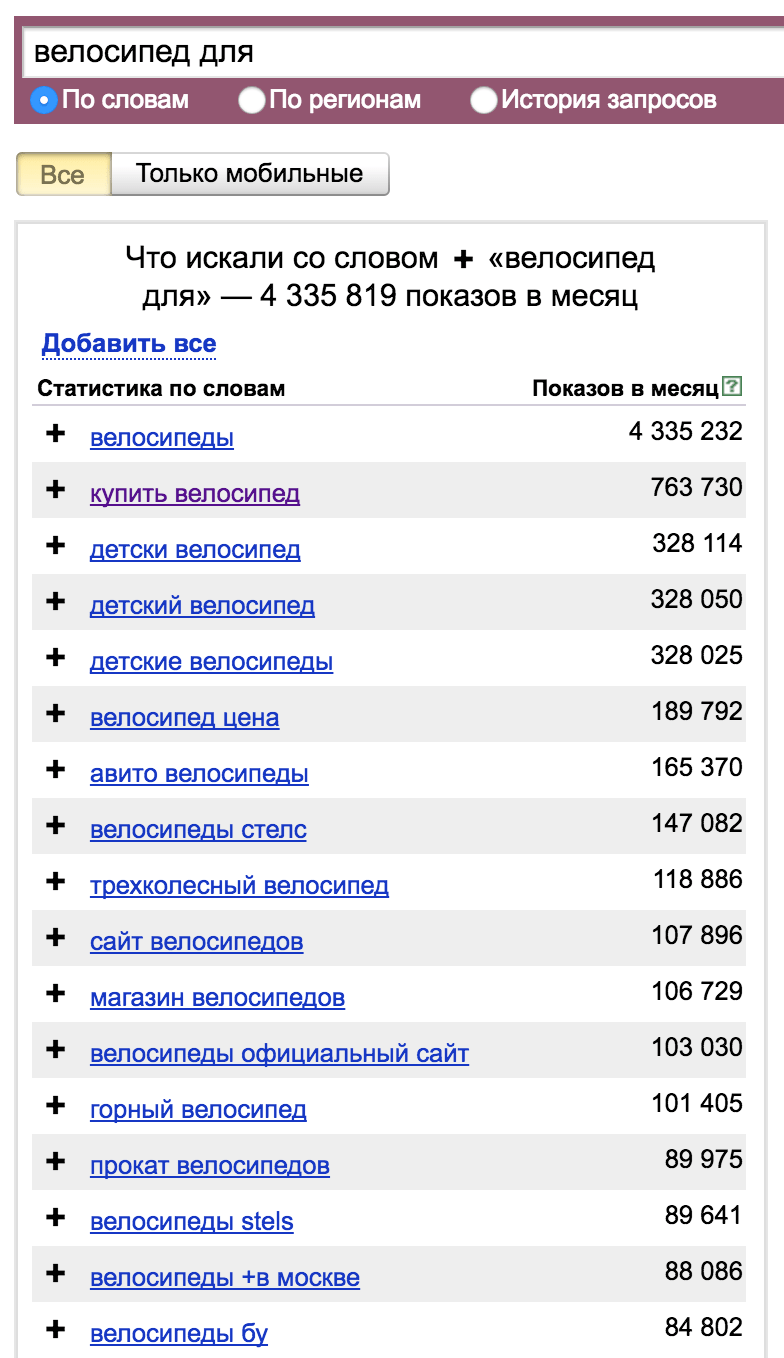

Представьте, что вы хотите узнать сколько человек желает купить авиабилеты в Москву. Если вы наберете [авиабилеты в Москву], то получите 716 174 общей частотности, но в эту частотность входят и запросы [авиабилеты из Москвы], [авиабилеты Москва], [москва сочи авиабилеты] и другие.
Но если вы введете запрос [авиабилеты + в Москву], то увидите 66 841 общей частотности. Цифры отличаются в 10 раз, надеюсь, что вы не забудете указать «+»
В сервисе Яндекс Вордстат есть возможность проанализировать частотность запросов по необходимому региону. Иногда это бывает очень полезно.

В некоторых сферах деятельности вы сможете найти для себя подходящие запросы, которые встречаются только в определенных регионах. Например, названия географических объектов.
Также предусмотрен отдельный функционал, где вы сможете посмотреть популярность любого ключевого слова в разных регионах.

Сезонность (история запросов) - очень полезный функционал с помощью которого можно проанализировать частотность по ключевому слову в разные периоды времени. Данные хранятся за 2 года.
Например, вот так выглядит спрос на авиабилеты в Москву в разное время года:

Дополнительные операторы
Есть некоторые операторы, которыми пользуются квалифицированные специалисты. Если вы только начинаете осваивать поисковую оптимизацию, то не стоит фокусировать на них внимание.
Оператор «-»
Оператор «-» позволяет убрать ненужные слова (по аналогии с директом).


Оператор «|» (или)
Оператор «|» (или) позволяет получить результат сразу по нескольким условиям.

Оператор «()» (группировка)
Оператор «()» (группировка) позволяет комбинировать условия.






