Правильная постановка вопроса должна быть такой: как натренировать сою собственную нейросеть? Писать сеть самому не нужно, нужно взять какую-то из готовых реализаций, которых есть множество, предыдущие авторы давали ссылки. Но сама по себе эта реализация подобна компьютеру, в который не закачали никаких программ. Для того, чтобы сеть решала вашу задачу, ее нужно научить.
И тут возникает собственно самое важное, что вам для этого потребуется: ДАННЫЕ. Много примеров задач, которые будут подаваться на вход нейросети, и правильные ответы на эти задачи. Нейросеть будет на этом учиться самостоятельно давать эти правильные ответы.
И вот тут возникает куча деталей и нюансов, которые нужно знать и понимать, чтобы это все имело шанс дать приемлемый результат. Осветить их все здесь нереально, поэтому просто перечислю некоторые пункты. Во-первых, объем данных. Это очень важный момент. Крупные компании, деятельность которых связана с машинным обучением, обычно содержат специальные отделы и штат сотрудников, занимающихся только сбором и обработкой данных для обучения нейросетей. Нередко данные приходится покупать, и вся эта деятельность выливается в заметную статью расходов. Во-вторых, представление данных. Если каждый объект в вашей задаче представлен относительно небольшим числом числовых параметров, то есть шанс, что их можно прямо в таком сыром виде дать нейросети, и получить приемлемый результат на выходе. Но если объекты сложные (картинки, звук, объекты переменной размерности), то скорее всего придется потратить время и силы на выделение из них содержательных для решаемой задачи признаков. Одно только это может занять очень много времени и иметь гораздо более влияние на итоговый результат, чем даже вид и архитектура выбранной для использования нейросети.
Нередки случаи, когда реальные данные оказываются слишком сырыми и непригодными для использования без предварительной обработки: содержат пропуски, шумы, противоречия и ошибки.
Данные должны быть собраны тоже не абы как, а грамотно и продуманно. Иначе обученная сеть может вести себя странно и даже решать совсем не ту задачу, которую предполагал автор.
Также нужно представлять себе, как грамотно организовать процесс обучения, чтобы сеть не оказалась переученной. Сложность сети нужно выбирать исходя из размерности данных и их количества. Часть данных нужно отложить для теста и при обучении не использовать, чтобы оценить реальное качество работы. Иногда различным объектам из обучающего множества нужно приписать различный вес. Иногда эти веса полезно варьировать в процессе обучения. Иногда полезно начинать обучение на части данных, а по мере обучения добавлять оставшиеся данные. В общем, это можно сравнить с кулинарией: у каждой хозяйки свои приемы готовки даже одинаковых блюд.
Многие из терминов в нейронных сетях связаны с биологией, поэтому давайте начнем с самого начала:
Мозг - штука сложная, но и его можно разделить на несколько основных частей и операций:

Возбудитель может быть и внутренним (например, образ или идея):

А теперь взглянем на основные и упрощенные части мозга:

Мозг вообще похож на кабельную сеть.
Нейрон - основная единица исчислений в мозге, он получает и обрабатывает химические сигналы других нейронов, и, в зависимости от ряда факторов, либо не делает ничего, либо генерирует электрический импульс, или Потенциал Действия, который затем через синапсы подает сигналы соседним связанным нейронам:

Сны, воспоминания, саморегулируемые движения, рефлексы да и вообще все, что вы думаете или делаете - все происходит благодаря этому процессу: миллионы, или даже миллиарды нейронов работают на разных уровнях и создают связи, которые создают различные параллельные подсистемы и представляют собой биологическую нейронную сеть .
Разумеется, это всё упрощения и обобщения, но благодаря им мы можем описать простую
нейронную сеть:

И описать её формализовано с помощью графа:

Тут требуются некоторые пояснения. Кружки - это нейроны, а линии - это связи между ними,
и, чтобы не усложнять на этом этапе, взаимосвязи
представляют собой прямое передвижение информации слева направо
. Первый нейрон в данный момент активен и выделен серым. Также мы присвоили ему число (1 - если он работает, 0 - если нет). Числа между нейронами показывают вес
связи.
Графы выше показывают момент времени сети, для более точного отображения, нужно разделить его на временные отрезки:

Для создания своей нейронной сети нужно понимать, как веса влияют на нейроны и как нейроны обучаются. В качестве примера возьмем кролика (тестового кролика) и поставим его в условия классического эксперимента.

Когда на них направляют безопасную струю воздуха, кролики, как и люди, моргают:

Эту модель поведения можно нарисовать графами:

Как и в предыдущей схеме, эти графы показывают только тот момент, когда кролик чувствует дуновение, и мы таким образом кодируем дуновение как логическое значение. Помимо этого мы вычисляем, срабатывает ли второй нейрон, основываясь на значении веса. Если он равен 1, то сенсорный нейрон срабатывает, мы моргаем; если вес меньше 1, мы не моргаем: у второго нейрона предел - 1.
Введем еще один элемент - безопасный звуковой сигнал:

Мы можем смоделировать заинтересованность кролика так:

Основное отличие в том, что сейчас вес равен нулю
, поэтому моргающего кролика мы не получили, ну, пока, по крайней мере. Теперь научим кролика моргать по команде, смешивая
раздражители (звуковой сигнал и дуновение):

Важно, что эти события происходят в разные временные эпохи , в графах это будет выглядеть так:

Сам по себе звук ничего не делает, но воздушный поток по-прежнему заставляет кролика моргать, и мы показываем это через веса, умноженные на раздражители (красным).
Обучение сложному поведению можно упрощённо выразить как постепенное изменение веса между связанными нейронами с течением времени.
Чтобы обучить кролика, повторим действия:

Для первых трех попыток схемы будут выглядеть так:

Обратите внимание, что вес для звукового раздражителя растет после каждого повтора (выделено красным), это значение сейчас произвольное - мы выбрали 0.30, но число может быть каким угодно, даже отрицательным. После третьего повтора вы не заметите изменения в поведении кролика, но после четвертого повтора произойдет нечто удивительное - поведение изменится.

Мы убрали воздействие воздухом, но кролик все еще моргает, услышав звуковой сигнал! Объяснить это поведение может наша последняя схемка:

Мы обучили кролика реагировать на звук морганием.

В условиях реального эксперимента такого рода может потребоваться более 60 повторений для достижения результата.
Теперь мы оставим биологический мир мозга и кроликов и попробуем адаптировать всё, что
узнали, для создания искусственной нейросети. Для начала попробуем сделать простую задачу.
Допустим, у нас есть машина с четырьмя кнопками, которая выдает еду при нажатии правильной
кнопки (ну, или энергию, если вы робот). Задача - узнать, какая кнопка выдает вознаграждение:

Мы можем изобразить (схематично), что делает кнопка при нажатии следующим образом:

Такую задачу лучше решать целиком, поэтому давайте посмотрим на все возможные результаты, включая правильный:

Нажмите на 3-ю кнопку, чтобы получить свой ужин.
Чтобы воспроизвести нейронную сеть в коде, нам для начала нужно сделать модель или график, с которым можно сопоставить сеть. Вот один подходящий под задачу график, к тому же он хорошо отображает свой биологический аналог:

Эта нейронная сеть просто получает входящую информацию - в данном случае это будет восприятие того, какую кнопку нажали. Далее сеть заменяет входящую информацию на веса и делает вывод на основе добавления слоя. Звучит немного запутанно, но давайте посмотрим, как в нашей модели представлена кнопка:

Обратите внимание, что все веса равны 0, поэтому нейронная сеть, как младенец, совершенно пуста, но полностью взаимосвязана.
Таким образом мы сопоставляем внешнее событие с входным слоем нейронной сети и вычисляем значение на ее выходе. Оно может совпадать или не совпадать с реальностью, но это мы пока проигнорируем и начнем описывать задачу понятным компьютеру способом. Начнем с ввода весов (будем использовать JavaScript):
Var inputs = ;
var weights = ;
// Для удобства эти векторы можно назвать
Следующий шаг - создание функции, которая собирает входные значения и веса и рассчитывает значение на выходе:
Function evaluateNeuralNetwork(inputVector, weightVector){
var result = 0;
inputVector.forEach(function(inputValue, weightIndex) {
layerValue = inputValue*weightVector;
result += layerValue;
});
return (result.toFixed(2));
}
// Может казаться комплексной, но все, что она делает - это сопоставляет пары вес/ввод и добавляет результат
Как и ожидалось, если мы запустим этот код, то получим такой же результат, как в нашей модели или графике…
EvaluateNeuralNetwork(inputs, weights); // 0.00
Живой пример: Neural Net 001 .
Следующим шагом в усовершенствовании нашей нейросети будет способ проверки её собственных выходных или результирующих значений сопоставимо реальной ситуации,
давайте сначала закодируем эту конкретную реальность в переменную:

Чтобы обнаружить несоответствия (и сколько их), мы добавим функцию ошибки:
Error = Reality - Neural Net Output
С ней мы можем оценивать работу нашей нейронной сети:

Но что более важно - как насчет ситуаций, когда реальность дает положительный результат?

Теперь мы знаем, что наша модель нейронной сети не работает (и знаем, насколько), здорово! А здорово это потому, что теперь мы можем использовать функцию ошибки для управления нашим обучением. Но всё это обретет смысл в том случае, если мы переопределим функцию ошибок следующим образом:
Error = Desired Output - Neural Net Output
Неуловимое, но такое важное расхождение, молчаливо показывающее, что мы будем
использовать ранее полученные результаты для сопоставления с будущими действиями
(и для обучения, как мы потом увидим). Это существует и в реальной жизни, полной
повторяющихся паттернов, поэтому оно может стать эволюционной стратегией (ну, в
большинстве случаев).
Var input = ;
var weights = ;
var desiredResult = 1;
И новую функцию:
Function evaluateNeuralNetError(desired,actual) {
return (desired - actual);
}
// After evaluating both the Network and the Error we would get:
// "Neural Net output: 0.00 Error: 1"
Живой пример: Neural Net 002 .
Подведем промежуточный итог . Мы начали с задачи, сделали её простую модель в виде биологической нейронной сети и получили способ измерения её производительности по сравнению с реальностью или желаемым результатом. Теперь нам нужно найти способ исправления несоответствия - процесс, который как и для компьютеров, так и для людей можно рассматривать как обучение.
Как обучать нейронную сеть?
Основа обучения как биологической, так и искусственной нейронной сети - это повторение
и алгоритмы обучения
, поэтому мы будем работать с ними по отдельности. Начнем с
обучающих алгоритмов.
В природе под алгоритмами обучения понимаются изменения физических или химических
характеристик нейронов после проведения экспериментов:

Драматическая иллюстрация того, как два нейрона меняются по прошествии времени в коде и нашей модели «алгоритм обучения» означает, что мы просто будем что-то менять в течение какого-то времени, чтобы облегчить свою жизнь. Поэтому давайте добавим переменную для обозначения степени облегчения жизни:
Var learningRate = 0.20;
// Чем больше значение, тем быстрее будет процесс обучения:)
И что это изменит?
Это изменит веса (прям как у кролика!), особенно вес вывода, который мы хотим получить:

Как кодировать такой алгоритм - ваш выбор, я для простоты добавляю коэффициент обучения к весу, вот он в виде функции:
Function learn(inputVector, weightVector) {
weightVector.forEach(function(weight, index, weights) {
if (inputVector > 0) {
weights = weight + learningRate;
}
});
}
При использовании эта обучающая функция просто добавит наш коэффициент обучения к вектору веса активного нейрона
, до и после круга обучения (или повтора) результаты будут такими:
// Original weight vector:
// Neural Net output: 0.00 Error: 1
learn(input, weights);
// New Weight vector:
// Neural Net output: 0.20 Error: 0.8
// Если это не очевидно, вывод нейронной сети близок к 1 (выдача курицы) - то, чего мы и
хотели, поэтому можно сделать вывод, что мы движемся в правильном направлении
Живой пример: Neural Net 003 .
Окей, теперь, когда мы движемся в верном направлении, последней деталью этой головоломки будет внедрение повторов .
Это не так уж и сложно, в природе мы просто делаем одно и то же снова и снова, а в коде мы просто указываем количество повторов:
Var trials = 6;
И внедрение в нашу обучающую нейросеть функции количества повторов будет выглядеть так:
Function train(trials) {
for (i = 0; i < trials; i++) {
neuralNetResult = evaluateNeuralNetwork(input, weights);
learn(input, weights);
}
}
Ну и наш окончательный отчет:
Neural Net output: 0.00 Error: 1.00 Weight Vector:
Neural Net output: 0.20 Error: 0.80 Weight Vector:
Neural Net output: 0.40 Error: 0.60 Weight Vector:
Neural Net output: 0.60 Error: 0.40 Weight Vector:
Neural Net output: 0.80 Error: 0.20 Weight Vector:
Neural Net output: 1.00 Error: 0.00 Weight Vector:
// Chicken Dinner !
Живой пример: Neural Net 004 .
Теперь у нас есть вектор веса, который даст только один результат (курицу на ужин), если входной вектор соответствует реальности (нажатие на третью кнопку).
Так что же такое классное мы только что сделали?
В этом конкретном случае наша нейронная сеть (после обучения) может распознавать входные данные и говорить, что приведет к желаемому результату (нам всё равно нужно будет программировать конкретные ситуации):

Кроме того, это масштабируемая модель, игрушка и инструмент для нашего с вами обучения. Мы смогли узнать что-то новое о машинном обучении, нейронных сетях и искусственном интеллекте.
Предостережение пользователям:
- Механизм хранения изученных весов не предусмотрен, поэтому данная нейронная сеть забудет всё, что знает. При обновлении или повторном запуске кода нужно не менее шести успешных повторов, чтобы сеть полностью обучилась, если вы считаете, что человек или машина будут нажимать на кнопки в случайном порядке… Это займет какое-то время.
- Биологические сети для обучения важным вещам имеют скорость обучения 1, поэтому нужен будет только один успешный повтор.
- Существует алгоритм обучения, который очень напоминает биологические нейроны, у него броское название: правило widroff-hoff , или обучение widroff-hoff .
- Пороги нейронов (1 в нашем примере) и эффекты переобучения (при большом количестве повторов результат будет больше 1) не учитываются, но они очень важны в природе и отвечают за большие и сложные блоки поведенческих реакций. Как и отрицательные веса.
Заметки и список литературы для дальнейшего чтения
Я пытался избежать математики и строгих терминов, но если вам интересно, то мы построили перцептрон , который определяется как алгоритм контролируемого обучения (обучение с учителем) двойных классификаторов - тяжелая штука.Биологическое строение мозга - тема не простая, отчасти из-за неточности, отчасти из-за его сложности. Лучше начинать с Neuroscience (Purves) и Cognitive Neuroscience (Gazzaniga). Я изменил и адаптировал пример с кроликом из Gateway to Memory (Gluck), которая также является прекрасным проводником в мир графов.
Еще один шикарный ресурс An Introduction to Neural Networks (Gurney), подойдет для всех ваших нужд, связанных с ИИ.
А теперь на Python! Спасибо Илье Андшмидту за предоставленную версию на Python:
Inputs =
weights =
desired_result = 1
learning_rate = 0.2
trials = 6
def evaluate_neural_network(input_array, weight_array):
result = 0
for i in range(len(input_array)):
layer_value = input_array[i] * weight_array[i]
result += layer_value
print("evaluate_neural_network: " + str(result))
print("weights: " + str(weights))
return result
def evaluate_error(desired, actual):
error = desired - actual
print("evaluate_error: " + str(error))
return error
def learn(input_array, weight_array):
print("learning...")
for i in range(len(input_array)):
if input_array[i] > 0:
weight_array[i] += learning_rate
def train(trials):
for i in range(trials):
neural_net_result = evaluate_neural_network(inputs, weights)
learn(inputs, weights)
train(trials)
А теперь на GO! За эту версию благодарю Кирана Мэхера.
Package main import ("fmt" "math") func main() { fmt.Println("Creating inputs and weights ...") inputs:= float64{0.00, 0.00, 1.00, 0.00} weights:= float64{0.00, 0.00, 0.00, 0.00} desired:= 1.00 learningRate:= 0.20 trials:= 6 train(trials, inputs, weights, desired, learningRate) } func train(trials int, inputs float64, weights float64, desired float64, learningRate float64) { for i:= 1; i < trials; i++ { weights = learn(inputs, weights, learningRate) output:= evaluate(inputs, weights) errorResult:= evaluateError(desired, output) fmt.Print("Output: ") fmt.Print(math.Round(output*100) / 100) fmt.Print("\nError: ") fmt.Print(math.Round(errorResult*100) / 100) fmt.Print("\n\n") } } func learn(inputVector float64, weightVector float64, learningRate float64) float64 { for index, inputValue:= range inputVector { if inputValue > 0.00 { weightVector = weightVector + learningRate } } return weightVector } func evaluate(inputVector float64, weightVector float64) float64 { result:= 0.00 for index, inputValue:= range inputVector { layerValue:= inputValue * weightVector result = result + layerValue } return result } func evaluateError(desired float64, actual float64) float64 { return desired - actual }
Вы можете помочь и перевести немного средств на развитие сайта
В этот раз я решил изучить нейронные сети. Базовые навыки в этом вопросе я смог получить за лето и осень 2015 года. Под базовыми навыками я имею в виду, что могу сам создать простую нейронную сеть с нуля. Примеры можете найти в моих репозиториях на GitHub. В этой статье я дам несколько разъяснений и поделюсь ресурсами, которые могут пригодиться вам для изучения.
Шаг 1. Нейроны и метод прямого распространения
Так что же такое «нейронная сеть»? Давайте подождём с этим и сперва разберёмся с одним нейроном.
Нейрон похож на функцию: он принимает на вход несколько значений и возвращает одно.
Круг ниже обозначает искусственный нейрон. Он получает 5 и возвращает 1. Ввод - это сумма трёх соединённых с нейроном синапсов (три стрелки слева).
В левой части картинки мы видим 2 входных значения (зелёного цвета) и смещение (выделено коричневым цветом).
Входные данные могут быть численными представлениями двух разных свойств. Например, при создании спам-фильтра они могли бы означать наличие более чем одного слова, написанного ЗАГЛАВНЫМИ БУКВАМИ, и наличие слова «виагра».
Входные значения умножаются на свои так называемые «веса», 7 и 3 (выделено синим).
Теперь мы складываем полученные значения со смещением и получаем число, в нашем случае 5 (выделено красным). Это - ввод нашего искусственного нейрона.

Потом нейрон производит какое-то вычисление и выдает выходное значение. Мы получили 1, т.к. округлённое значение сигмоиды в точке 5 равно 1 (более подробно об этой функции поговорим позже).
Если бы это был спам-фильтр, факт вывода 1 означал бы то, что текст был помечен нейроном как спам.

Иллюстрация нейронной сети с Википедии.
Если вы объедините эти нейроны, то получите прямо распространяющуюся нейронную сеть - процесс идёт от ввода к выводу, через нейроны, соединённые синапсами, как на картинке слева.
Шаг 2. Сигмоида
После того, как вы посмотрели уроки от Welch Labs, хорошей идеей было бы ознакомиться с четвертой неделей курса по машинному обучению от Coursera , посвящённой нейронным сетям - она поможет разобраться в принципах их работы. Курс сильно углубляется в математику и основан на Octave, а я предпочитаю Python. Из-за этого я пропустил упражнения и почерпнул все необходимые знания из видео.

Сигмоида просто-напросто отображает ваше значение (по горизонтальной оси) на отрезок от 0 до 1.
Первоочередной задачей для меня стало изучение сигмоиды , так как она фигурировала во многих аспектах нейронных сетей. Что-то о ней я уже знал из третьей недели вышеупомянутого курса , поэтому я пересмотрел видео оттуда.
Но на одних видео далеко не уедешь. Для полного понимания я решил закодить её самостоятельно. Поэтому я начал писать реализацию алгоритма логистической регрессии (который использует сигмоиду).
Это заняло целый день, и вряд ли результат получился удовлетворительным. Но это неважно, ведь я разобрался, как всё работает. Код можно увидеть .
Вам необязательно делать это самим, поскольку тут требуются специальные знания - главное, чтобы вы поняли, как устроена сигмоида.
Шаг 3. Метод обратного распространения ошибки
Понять принцип работы нейронной сети от ввода до вывода не так уж и сложно. Гораздо сложнее понять, как нейронная сеть обучается на наборах данных. Использованный мной принцип называется
Нейросети сейчас в моде, и не зря. С их помощью можно, к примеру, распознавать предметы на картинках или, наоборот, рисовать ночные кошмары Сальвадора Дали. Благодаря удобным библиотекам простейшие нейросети создаются всего парой строк кода, не больше уйдет и на обращение к искусственному интеллекту IBM.
Теория
Биологи до сих пор не знают, как именно работает мозг, но принцип действия отдельных элементов нервной системы неплохо изучен. Она состоит из нейронов - специализированных клеток, которые обмениваются между собой электрохимическими сигналами. У каждого нейрона имеется множество дендритов и один аксон. Дендриты можно сравнить со входами, через которые в нейрон поступают данные, аксон же служит его выходом. Соединения между дендритами и аксонами называют синапсами. Они не только передают сигналы, но и могут менять их амплитуду и частоту.
Преобразования, которые происходят на уровне отдельных нейронов, очень просты, однако даже совсем небольшие нейронные сети способны на многое. Все многообразие поведения червя Caenorhabditis elegans - движение, поиск пищи, различные реакции на внешние раздражители и многое другое - закодировано всего в трех сотнях нейронов. И ладно черви! Даже муравьям хватает 250 тысяч нейронов, а то, что они делают, машинам определенно не под силу.
Почти шестьдесят лет назад американский исследователь Фрэнк Розенблатт попытался создать компьютерную систему, устроенную по образу и подобию мозга, однако возможности его творения были крайне ограниченными. Интерес к нейросетям с тех пор вспыхивал неоднократно, однако раз за разом выяснялось, что вычислительной мощности не хватает на сколько-нибудь продвинутые нейросети. За последнее десятилетие в этом плане многое изменилось.
Электромеханический мозг с моторчиком

Машина Розенблатта называлась Mark I Perceptron. Она предназначалась для распознавания изображений - задачи, с которой компьютеры до сих пор справляются так себе. Mark I был снабжен подобием сетчатки глаза: квадратной матрицей из 400 фотоэлементов, двадцать по вертикали и двадцать по горизонтали. Фотоэлементы в случайном порядке подключались к электронным моделям нейронов, а они, в свою очередь, к восьми выходам. В качестве синапсов, соединяющих электронные нейроны, фотоэлементы и выходы, Розенблатт использовал потенциометры. При обучении перцептрона 512 шаговых двигателей автоматически вращали ручки потенциометров, регулируя напряжение на нейронах в зависимости от точности результата на выходе.
Вот в двух словах, как работает нейросеть. Искусственный нейрон, как и настоящий, имеет несколько входов и один выход. У каждого входа есть весовой коэффициент. Меняя эти коэффициенты, мы можем обучать нейронную сеть. Зависимость сигнала на выходе от сигналов на входе определяет так называемая функция активации.
В перцептроне Розенблатта функция активации складывала вес всех входов, на которые поступила логическая единица, а затем сравнивала результат с пороговым значением. Ее минус заключался в том, что незначительное изменение одного из весовых коэффициентов при таком подходе способно оказать несоразмерно большое влияние на результат. Это затрудняет обучение.
В современных нейронных сетях обычно используют нелинейные функции активации, например сигмоиду. К тому же у старых нейросетей было слишком мало слоев. Сейчас между входом и выходом обычно располагают один или несколько скрытых слоев нейронов. Именно там происходит все самое интересное.

Чтобы было проще понять, о чем идет речь, посмотри на эту схему. Это нейронная сеть прямого распространения с одним скрытым слоем. Каждый кружок соответствует нейрону. Слева находятся нейроны входного слоя. Справа - нейрон выходного слоя. В середине располагается скрытый слой с четырьмя нейронами. Выходы всех нейронов входного слоя подключены к каждому нейрону первого скрытого слоя. В свою очередь, входы нейрона выходного слоя связаны со всеми выходами нейронов скрытого слоя.
Не все нейронные сети устроены именно так. Например, существуют (хотя и менее распространены) сети, у которых сигнал с нейронов подается не только на следующий слой, как у сети прямого распространения с нашей схемы, но и в обратном направлении. Такие сети называются рекуррентными. Полностью соединенные слои - это тоже лишь один из вариантов, и одной из альтернатив мы даже коснемся.
Практика
Итак, давай попробуем построить простейшую нейронную сеть своими руками и разберемся в ее работе по ходу дела. Мы будем использовать Python с библиотекой Numpy (можно было бы обойтись и без Numpy, но с Numpy линейная алгебра отнимет меньше сил). Рассматриваемый пример основан на коде Эндрю Траска.
Нам понадобятся функции для вычисления сигмоиды и ее производной:
Продолжение доступно только подписчикам
Вариант 1. Оформи подписку на «Хакер», чтобы читать все материалы на сайте
Подписка позволит тебе в течение указанного срока читать ВСЕ платные материалы сайта. Мы принимаем оплату банковскими картами, электронными деньгами и переводами со счетов мобильных операторов.
Что такое нейронная сеть?

Нейронная сеть - это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1 , Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей - это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:Классификация - распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание - возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание - в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?

Нейрон - это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.

Важно помнить , что нейроны оперируют числами в диапазоне или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ - это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?

Синапс это связь между двумя нейронами. У синапсов есть 1 параметр - вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример - смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов - это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить , что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?

В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H - скрытый нейрон, а буквой w - веса. Из формулы видно, что входная информация - это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации
Функция активации - это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия - это диапазон значений.Линейная функция
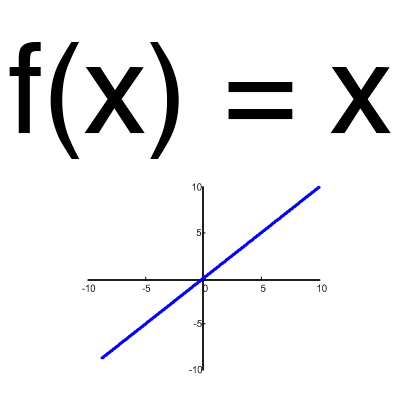
Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид

Это самая распространенная функция активации, ее диапазон значений . Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс

Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет - это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.
Важно не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.






