- Перевод
Если вы уже освоились с основами терминала, возможно, вы уже готовы к тому, чтобы комбинировать изученные команды. Иногда выполнения команд оболочки по одной вполне достаточно для решения некоей задачи, но в некоторых случаях вводить команду за командой слишком утомительно и нерационально. В подобной ситуации нам пригодятся некоторые особые символы, вроде угловых скобок.
Для оболочки, интерпретатора команд Linux, эти дополнительные символы - не пустая трата места на экране. Они - мощные команды, которые могут связывать воедино различные фрагменты информации, разделять то, что было до этого цельным, и делать ещё много всего. Одна из самых простых, и, в то же время, мощных и широко используемых возможностей оболочки - это перенаправление стандартных потоков ввода/вывода.
Три стандартных потока ввода/вывода
Для того, чтобы понять то, о чём мы будем тут говорить, важно знать, откуда берутся данные, которые можно перенаправлять, и куда они идут. В Linux существует три стандартных потока ввода/вывода данных.Первый - это стандартный поток ввода (standard input). В системе это - поток №0 (так как в компьютерах счёт обычно начинается с нуля). Номера потоков ещё называют дескрипторами. Этот поток представляет собой некую информацию, передаваемую в терминал, в частности - инструкции, переданные в оболочку для выполнения. Обычно данные в этот поток попадают в ходе ввода их пользователем с клавиатуры.
Второй поток - это стандартный поток вывода (standard output), ему присвоен номер 1. Это поток данных, которые оболочка выводит после выполнения каких-то действий. Обычно эти данные попадают в то же окно терминала, где была введена команда, вызвавшая их появление.
И, наконец, третий поток - это стандартный поток ошибок (standard error), он имеет дескриптор 2. Этот поток похож на стандартный поток вывода, так как обычно то, что в него попадает, оказывается на экране терминала. Однако, он, по своей сути, отличается от стандартного вывода, как результат, этими потоками, при желании, можно управлять раздельно. Это полезно, например, в следующей ситуации. Есть команда, которая обрабатывает большой объём данных, выполняя сложную и подверженную ошибкам операцию. Нужно, чтобы полезные данные, которые генерирует эта команда, не смешивались с сообщениями об ошибках. Реализуется это благодаря раздельному перенаправлению потоков вывода и ошибок.
Как вы, вероятно, уже догадались, перенаправление ввода/вывода означает работу с вышеописанными потоками и перенаправление данных туда, куда нужно программисту. Делается это с использованием символов > и < в различных комбинациях, применение которых зависит от того, куда, в итоге, должны попасть перенаправляемые данные.
Перенаправление стандартного потока вывода
Предположим, вы хотите создать файл, в который будут записаны текущие дата и время. Дело упрощает то, что имеется команда, удачно названная date , которая возвращает то, что нам нужно. Обычно команды выводят данные в стандартный поток вывода. Для того, чтобы эти данные оказались в файле, нужно добавить символ > после команды, перед именем целевого файла. До и после > надо поставить пробел.При использовании перенаправления любой файл, указанный после > будет перезаписан. Если в файле нет ничего ценного и его содержимое можно потерять, в нашей конструкции допустимо использовать уже существующий файл. Обычно же лучше использовать в подобном случае имя файла, которого пока не существует. Этот файл будет создан после выполнения команды. Назовём его date.txt . Расширение файла после точки обычно особой роли не играет, но расширения помогают поддерживать порядок. Итак, вот наша команда:
$ date > date.txt
Нельзя сказать, что сама по себе эта команда невероятно полезна, однако, основываясь на ней, мы уже можем сделать что-то более интересное. Скажем, вы хотите узнать, как меняются маршруты вашего трафика, идущего через интернет к некоей конечной точке, ежедневно записывая соответствующие данные. В решении этой задачи поможет команда traceroute , которая сообщает подробности о маршруте трафика между нашим компьютером и конечной точкой, задаваемой при вызове команды в виде URL. Данные включают в себя сведения обо всех маршрутизаторах, через которые проходит трафик.
Так как файл с датой у нас уже есть, будет вполне оправдано просто присоединить к этому файлу данные, полученные от traceroute . Для того, чтобы это сделать, надо использовать два символа > , поставленные один за другим. В результате новая команда, перенаправляющая вывод в файл, но не перезаписывающая его, а добавляющая новые данные после старых, будет выглядеть так:
$ traceroute google.com >> date.txt
Теперь нам осталось лишь изменить имя файла на что-нибудь более осмысленное, используя команду mv , которой, в качестве первого аргумента, передаётся исходное имя файла, а в качестве второго - новое:
$ mv date.txt trace1.txt
Перенаправление стандартного потока ввода
Используя знак < вместо > мы можем перенаправить стандартный ввод, заменив его содержимым файла.Предположим, имеется два файла: list1.txt и list2.txt , каждый из которых содержит неотсортированный список строк. В каждом из списков имеются уникальные для него элементы, но некоторые из элементов список совпадают. Мы можем найти строки, которые имеются и в первом, и во втором списках, применив команду comm , но прежде чем её использовать, списки надо отсортировать.
Существует команда sort , которая возвращает отсортированный список в терминал, не сохраняя отсортированные данные в файл, из которого они были взяты. Можно отправить отсортированную версию каждого списка в новый файл, используя команду > , а затем воспользоваться командой comm . Однако, такой подход потребует как минимум двух команд, хотя то же самое можно сделать в одной строке, не создавая при этом ненужных файлов.
Итак, мы можем воспользоваться командой < для перенаправления отсортированной версии каждого файла команде comm . Вот что у нас получилось:
$ comm <(sort list1.txt) <(sort list2.txt)
Круглые скобки тут имеют тот же смысл, что и в математике. Оболочка сначала обрабатывает команды в скобках, а затем всё остальное. В нашем примере сначала производится сортировка строк из файлов, а потом то, что получилось, передаётся команде comm , которая затем выводит результат сравнения списков.
Перенаправление стандартного потока ошибок
И, наконец, поговорим о перенаправлении стандартного потока ошибок. Это может понадобиться, например, для создания лог-файлов с ошибками или объединения в одном файле сообщений об ошибках и возвращённых некоей командой данных.Например, что если надо провести поиск во всей системе сведений о беспроводных интерфейсах, которые доступны пользователям, у которых нет прав суперпользователя? Для того, чтобы это сделать, можно воспользоваться мощной командой find .
Обычно, когда обычный пользователь запускает команду find по всей системе, она выводит в терминал и полезные данные и ошибки. При этом, последних обычно больше, чем первых, что усложняет нахождение в выводе команды того, что нужно. Решить эту проблему довольно просто: достаточно перенаправить стандартный поток ошибок в файл, используя команду 2> (напомним, 2 - это дескриптор стандартного потока ошибок). В результате на экран попадёт только то, что команда отправляет в стандартный вывод:
$ find / -name wireless 2> denied.txt
Как быть, если нужно сохранить результаты работы команды в отдельный файл, не смешивая эти данные со сведениями об ошибках? Так как потоки можно перенаправлять независимо друг от друга, в конец нашей конструкции можно добавить команду перенаправления стандартного потока вывода в файл:
$ find / -name wireless 2> denied.txt > found.txt
Обратите внимание на то, что первая угловая скобка идёт с номером - 2> , а вторая без него. Это так из-за того, что стандартный вывод имеет дескриптор 1, и команда > подразумевает перенаправление стандартного вывода, если номер дескриптора не указан.
И, наконец, если нужно, чтобы всё, что выведет команда, попало в один файл, можно перенаправить оба потока в одно и то же место, воспользовавшись командой &> :
$ find / -name wireless &> results.txt
Итоги
Тут мы разобрали лишь основы механизма перенаправления потоков в интерпретаторе командной строки Linux, однако даже то немногое, что вы сегодня узнали, даёт вам практически неограниченные возможности. И, кстати, как и всё остальное, что касается работы в терминале, освоение перенаправления потоков требует практики. Поэтому рекомендуем вам приступить к собственным экспериментам с > и < .Уважаемые читатели! Знаете ли вы интересные примеры использования перенаправления потоков в Linux, которые помогут новичкам лучше освоиться с этим приёмом работы в терминале?
Одна из самых интересных и полезных тем для системных администраторов и новых пользователей, которые только начинают разбираться в работе с терминалом - это перенаправление потоков ввода вывода Linux. Эта особенность терминала позволяет перенаправлять вывод команд в файл, или содержимое файла на ввод команды, объединять команды вместе, и образовать конвейеры команд.
В этой статье мы рассмотрим как выполняется перенаправление потоков ввода вывода в Linux, какие операторы для этого используются, а также где все это можно применять.
Все команды, которые мы выполняем, возвращают нам три вида данных:
- Результат выполнения команды, обычно текстовые данные, которые запросил пользователь;
- Сообщения об ошибках - информируют о процессе выполнения команды и возникших непредвиденных обстоятельствах;
- Код возврата - число, которое позволяет оценить правильно ли отработала программа.
В Linux все субстанции считаются файлами, в том числе и потоки ввода вывода linux - файлы. В каждом дистрибутиве есть три основных файла потоков, которые могут использовать программы, они определяются оболочкой и идентифицируются по номеру дескриптора файла:
- STDIN или 0 - этот файл связан с клавиатурой и большинство команд получают данные для работы отсюда;
- STDOUT или 1 - это стандартный вывод, сюда программа отправляет все результаты своей работы. Он связан с экраном, или если быть точным, то с терминалом, в котором выполняется программа;
- STDERR или 2 - все сообщения об ошибках выводятся в этот файл.
Перенаправление ввода / вывода позволяет заменить один из этих файлов на свой. Например, вы можете заставить программу читать данные из файла в файловой системе, а не клавиатуры, также можете выводить ошибки в файл, а не на экран и т д. Все это делается с помощью символов "<" и ">" .
Перенаправить вывод в файл
Все очень просто. Вы можете перенаправить вывод в файл с помощью символа >. Например, сохраним вывод команды top:
top -bn 5 > top.log
Опция -b заставляет программу работать в не интерактивном пакетном режиме, а n - повторяет операцию пять раз, чтобы получить информацию обо всех процессах. Теперь смотрим что получилось с помощью cat:

Символ ">" перезаписывает информацию из файла, если там уже что-то есть. Для добавления данных в конец используйте ">>" . Например, перенаправить вывод в файл linux еще для top:
top -bn 5 >> top.log
По умолчанию для перенаправления используется дескриптор файла стандартного вывода. Но вы можете указать это явно. Эта команда даст тот же результат:
top -bn 5 1>top.log
Перенаправить ошибки в файл
Чтобы перенаправить вывод ошибок в файл вам нужно явно указать дескриптор файла, который собираетесь перенаправлять. Для ошибок - это номер 2. Например, при попытке получения доступа к каталогу суперпользователя ls выдаст ошибку:

Вы можете перенаправить стандартный поток ошибок в файл так:
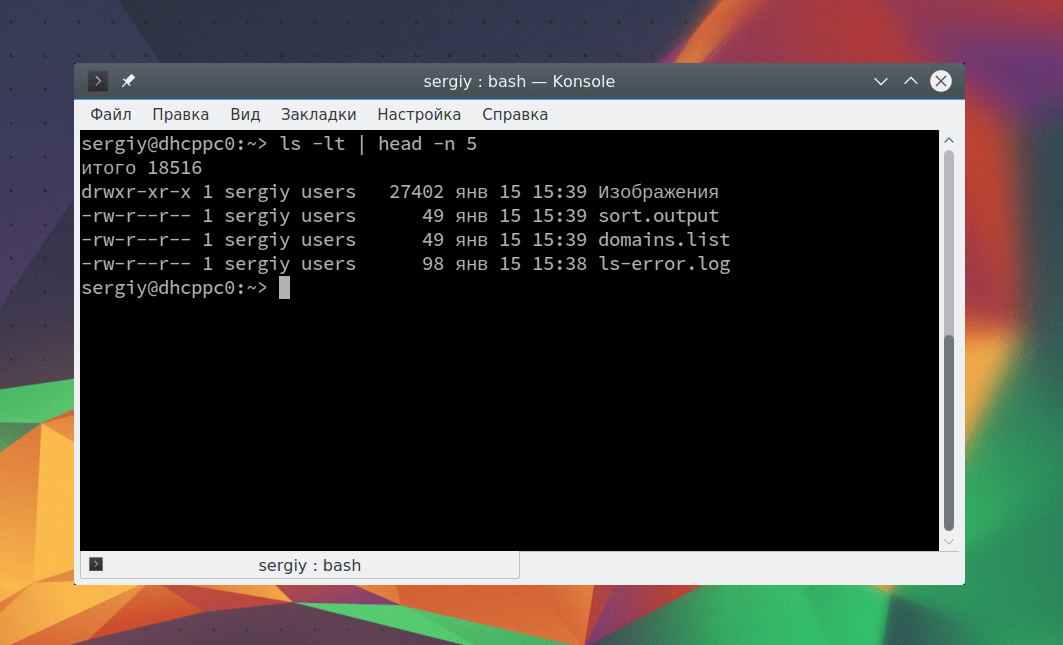
ls -l /root/ 2> ls-error.log
$ cat ls-error.log

Чтобы добавить данные в конец файла используйте тот же символ:
ls -l /root/ 2>>ls-error.log

Перенаправить стандартный вывод и ошибки в файл
Вы также можете перенаправить весь вывод, ошибки и стандартный поток вывода в один файл. Для этого есть два способа. Первый из них, более старый, состоит в том, чтобы передать оба дескриптора:
ls -l /root/ >ls-error.log 2>&1

Сначала будет отправлен вывод команды ls в файл ls-error.log c помощью первого символа перенаправления. Дальше в тот же самый файл будут направлены все ошибки. Второй метод проще:
ls -l /root/ &> ls-error.log
Также можно использовать добавление вместо перезаписи:
ls -l /root/ &>> ls-error.log
Стандартный ввод из файла
Большинство программ, кроме сервисов, получают данные для своей работы через стандартный ввод. По умолчанию стандартный ввод ожидает данных от клавиатуры. Но вы можете заставить программу читать данные из файла с помощью оператора "<" :
cat Вы также можете сразу же перенаправить вывод тоже в файл. Например, пересортируем список: sort Таким образом, мы в одной команде перенаправляем ввод вывод linux. Можно работать не только с файлами, но и перенаправлять вывод одной команды в качестве ввода другой. Это очень полезно для выполнения сложных операций. Например, выведем пять недавно измененных файлов: ls -lt | head -n 5 С помощью утилиты xargs вы можете комбинировать команды таким образом, чтобы стандартный ввод передавался в параметры. Например, скопируем один файл в несколько папок: echo test/ tmp/ | xargs -n 1 cp -v testfile.sh Здесь параметр -n 1 задает, что для одной команды нужно подставлять только один параметр, а опция -v в cp позволяет выводить подробную информацию о перемещениях. Еще одна, полезная в таких случаях команда - это tee. Она читает данные из стандартного ввода и записывает в стандартный вывод или файлы. Например: echo "Тест работы tee" | tee file1 В сочетании с другими командами все это может использоваться для создания сложных инструкций из нескольких команд. В этой статье мы рассмотрели основы перенаправления потоков ввода вывода Linux. Теперь вы знаете как перенаправить вывод в файл linux или вывод из файла. Это очень просто и удобно. Если у вас остались вопросы, спрашивайте в комментариях! Изучаем Linux, 101 Обработка текста в командной строке с использованием текстовых утилит GNU В этой статье вы познакомитесь с фильтрами
, которые позволяют строить сложные конвейеры
для манипуляций с текстом. Вы узнаете, как выводить текст, сортировать его, выполнять подсчет слов и строк, преобразовывать символы, а также о многом другом. Также вы научитесь работать с потоковым редактором sed
. В этой статье будут рассмотрены следующие темы: Эта серия статей поможет вам освоить задачи администрирования операционной системы Linux. Вы также можете использовать материал этих статей для подготовки к . Чтобы посмотреть описания статей этой серии и получить ссылки на них, обратитесь к нашему . Этот перечень постоянно дополняется новыми статьями по мере их готовности и содержит самые последние (по состоянию на апрель 2009 года) цели экзаменов сертификации LPIC-1. Если какая-либо статья отсутствует в перечне, можно найти ее более раннюю версию, соответствующую предыдущим целям LPIC-1 (до апреля 2009 года), обратившись к нашим . Эта статья поможет вам подготовиться к сдаче экзамена LPI 101 на администратора начального уровня (LPIC-1) и содержит материалы цели 103.2 темы 103. Цель имеет вес 3. Материал этой статьи соответствует целям экзамена LPI 101 по состоянию на апрель 2009 года. Всегда обращайтесь к Web-сайту программы сертификации LPIC, чтобы уточнить последние цели. Чтобы извлечь наибольшую пользу из наших статей, необходимо обладать базовыми знаниями о Linux и иметь работоспособный компьютер с Linux, на котором можно будет выполнять все встречающиеся команды. Иногда различные версии программ выводят результаты по-разному, поэтому содержимое листингов и рисунков может отличаться от того, что вы увидите на вашем компьютере. Ян – один из наших наиболее популярных и плодовитых авторов. Ознакомьтесь со (EN), опубликованными на сайте developerWorks. Вы можете найти контактные данные в и связаться с ним, а также с другими авторами и участниками ресурса My developerWorks. Фильтрация текста – это процесс получения входного текстового потока, выполнения неких преобразований над ним и передача измененных данных в выходной поток. Хотя входные или выходные данные могут поступать из файлов, в UNIX® и Linux фильтрация обычно осуществляется путем составления конвейеров из команд, в которых вывод одной команды передается по программному каналу
(или перенаправляется
) на вход следующей команде. Более подробно программные каналы и перенаправления рассматриваются в статье "Потоки, программные каналы и перенаправления
" (см. ), а сейчас давайте рассмотрим программные каналы и простые перенаправления вывода с помощью операторов | и >. Поток
– это всего лишь последовательность байтов, которые могут быть считаны или записаны с помощью библиотечных функций, скрывающих подробности реализации и работы устройств от приложений. Одна и та же программа может считывать или отправлять данные на терминал, в файл или сетевое местоположение с помощью потоков независимо от используемого устройства. В современных средах программирования и командных интерпретаторах используются три стандартных потока: Передаваемые командам параметры могут служить входными данными этих команд, а выходные данные могут выводиться на ваш терминал. Многие команды обработки текста (фильтры) могут получать входные данные либо из стандартного потока ввода, либо из файла. Чтобы передать вывод команды1 на вход команде2 (выступающей в качестве фильтра), необходимо соединить эти две команды оператором конвейеризации ввода/вывода (|). В листинге 1 показано, как перенаправить вывод команды echo на вход команде sort , которая сортирует полученный список слов. У любой из этих команд могут иметься опции или аргументы. С помощью оператора | можно также перенаправить вывод второй команды на вход третьей команде и так далее. Построение длинных конвейеров из команд, каждая из которых имеет свой ограниченный функционал – это распространенный в Linux и UNIX прием, используемый для решения поставленных задач. Иногда аргументом команды может являться не имя файла, а знак дефиса (-); это означает, что входные данные следует принимать со стандартного устройства ввода, а не из файла. Конечно, хорошо иметь возможность создавать конвейеры из нескольких команд и выводить результаты на экран терминала, однако иногда возникает необходимость сохранить вывод в файл. Для этого используется оператор перенаправления вывода (>). В оставшихся примерах этой статьи мы будем использовать небольшие файлы, поэтому давайте создадим директорию с именем lpi103-2 и перейдем в нее. После этого давайте перенаправим с помощью оператора > вывод команды echo в файл с именем text1. Эти действия показаны в листинге 2. Заметьте, что поскольку весь вывод перенаправляется в файл, он не отображается на экране. Теперь, когда у нас имеется несколько инструментов для конвейеризации и перенаправления, давайте рассмотрим несколько распространенных в Linux и UNIX команд обработки текста и фильтров. В этом разделе вы познакомитесь с некоторыми основными командами; для получения дополнительной информации о них обращайтесь к соответствующим man-страницам. После того, как вы создали файл test1, вы можете просмотреть его содержимое. Для вывода содержимого файла на стандартное устройство вывода используется команда cat (сокращенно от concatenate
– объединять). В листинге 3 на экран выводится содержимое только что созданного нами файла. Если не указать имя файла (или поставить вместо имени файла дефис), то команда cat принимает входные данные со стандартного устройства ввода. Давайте используем эту возможность (а также перенаправление вывода) для создания еще одного текстового файла, как показано в листинге 4. Другим примером простого фильтра является команда tac (перевернутое имя команды cat). Эта команда выполняет действие команды cat наоборот – строки файла выводятся в обратном порядке. Попробуйте самостоятельно выполнить следующую команду: В листинге 4 команда cat продолжает считывать данные с устройства stdin до тех пор, пока не будет достигнут конец файла. Чтобы обозначить конец файла, нажмите комбинацию клавиш Ctrl-d
(удерживайте Ctrl
и нажмите d
). Эта же комбинация клавиш используется для выхода из командного интерпретатора bash. Используйте клавишу табуляции, чтобы выстроить названия фруктов в столбец. Вы еще не забыли, что cat
– это сокращение от concatenate
? С помощью cat вы можете объединить несколько файлов и вывести их содержимое на экран. В листинге 5 показано содержимое двух файлов, которые мы создали. Обратите внимание на различное выравнивание содержимого двух текстовых файлов при выводе их на экран с помощью cat . Чтобы разобраться, почему это происходит, необходимо посмотреть на управляющие символы, которые присутствуют в файлах. Эти символы влияют на вывод текста, но не имеют визуального отображения, поэтому необходимо создать дамп
файла в формате, позволяющем увидеть и определить эти специальные символы. Для этих целей предназначена GNU-утилита od (O
ctal D
ump). Команда od имеет несколько опций; например, опция -A управляет основанием смещения файлов, а опция -t – формой выводимого содержимого. Основание может быть указано как o (восьмеричное, используется по умолчанию), d (десятичное), x (шестнадцатеричное) или n (смещения не отображаются). Вы можете выводить содержимое в виде восьмеричных, шестнадцатеричных, десятичных значений, значений с плавающей точкой, ASCII-символов с escape-последовательностями или именованных символов (nl – для новой строки, ht – для горизонтальной табуляции и т. д.). В листинге 6 показано несколько доступных форматов дампа файла text2 из нашего примера. Примечания:
Файлы, используемые в наших примерах, очень малы, но иногда вам могут встретиться большие файлы, которые необходимо разделить на несколько более мелких. Например, вам может потребоваться разбить один большой файл на несколько частей такого размера, чтобы их можно было записать на компакт-диски. Для этого можно использовать команду split , которая разбивает файлы таким образом, что впоследствии их можно легко собрать обратно в единый файл при помощи команды cat . По умолчанию имена файлов, создаваемых командой split , состоят из префикса "x", за которым следует суффикс "aa", "ab", "ac", ..., "ba", "bb" и так далее. Эти умолчания можно изменить с помощью различных опций. Вы также можете задавать размер выходных файлов и определять, будут ли они содержать определенное количество строк или просто иметь определенный размер в байтах. В листинге 7 показано разделение наших двух текстовых файлов с использованием различных префиксов для выходных файлов. Файл text1 мы разделили на файлы, содержащие максимум две строки, а файл text2 – на файлы максимальным размером в 18 байтов. Далее с помощью команды cat мы отобразили некоторые отдельные части, а также весь файл целиком, используя универсализацию файловых имен
, которая рассматривается в статье "Основы управления файлами и директориями
" (см. ). Обратите внимание на то, что файл с именем yaa не оканчивается символом новой строки, поэтому, когда мы вывели его содержимое на экран с помощью команды cat , наше приглашение сдвинулось вправо. Команда cat выводит полное содержимое файла. Это хорошо подходит для небольших файлов (например, для наших примеров), но что делать, если объем файла очень большой? Итак, для начала можно оценить размер файла с помощью команды wc (W
ord
C
ount – подсчет слов). Команда wc выводит количество содержащихся в файле строк и слов, а также размер файла в байтах, определить который можно также с помощью команды ls -l . В листинге 8 показан подробный вывод сведений о наших двух текстовых файлах, а также вывод команды wc . Различные опции позволяют вам управлять выводом команды wc или отображать другую информацию, например, максимальную длину строки. Для получения дополнительной информации обратитесь к man-странице. Две другие команды позволяют отображать либо первую часть файла (заголовок
), либо последнюю (хвост
). Эти команды так и называются – head и tail соответственно. Их можно использовать в качестве фильтров или передавать им в качестве аргумента имя файла. По умолчанию эти команды отображают 10 первых (или последних) строк файла или потока. В листинге 9 совместно используются команды dmesg (отображение информации о загрузке системы), wc , tail и
head ; в результате мы видим, что файл содержит 791 сообщение, выводим последние 10 из них, а затем выводим шесть сообщений, начиная с 15 от конца. Другим распространенным применением команды tail является слежение
за файлом; для этого используется опция -f и шаг, обычно равный одной строке. Это может оказаться полезным в том случае, если у вас имеется фоновый процесс, генерирующий вывод данных в файл, и вы хотите следить за ходом его выполнения. В этом режиме команда tail будет работать и выводить строки по мере их добавления в файл до тех пор, пока вы не завершите ее работу, нажав Ctrl-c
. Когда мы создавали наши файлы text1 и text2, в последнем из них были использованы символы табуляции. Иногда вам может потребоваться заменить символы табуляции на символы пробела и наоборот. Для этого предназначены команды expand и unexpand . В обеих командах опция -t позволяет устанавливать позиции табуляции. Если после этой опции указывается только одно значение, то позиции табуляции будут периодически расставляться через этот указанный интервал. В листинге 10 показано, как сократить символы табуляции в файле text2 до одиночных пробелов, а также приведена причудливая последовательность из команд expand и unexpand и нарушающая выравнивание текста в файле text2. К сожалению, вы не можете использовать команду unexpand для замены пробелов в файле text1 на символы табуляции, поскольку для преобразования в символ табуляции команде unexpand требуется, как минимум, два последовательных пробела. Однако вы можете использовать команду tr , которая преобразует символы из одного набора (набор1
) в соответствующие символы из другого набора (набор2
). В листинге 11 показан пример использования команды tr для преобразования пробелов в символы табуляции. Поскольку команда tr представляет собой фильтр в чистом виде, то входные данные для нее генерируются с помощью команды cat . В этом примере также показан пример использования дефиса (-) с целью указать cat на то, что ввод будет осуществляться со стандартного устройства; таким образом, мы можем объединить вывод команды tr с содержимым файла text2. Если вы не очень понимаете, что происходит в последних двух примерах, то попробуйте использовать команду od , чтобы последовательно выполнить каждую команду конвейера, например: Команда pr используется для форматирования файлов перед печатью. По умолчанию заголовок включает в себя имя файла, дату и время создания файла, номер страницы, а также две пустых строки нижнего колонтитула. Когда данные поступают из нескольких файлов или со стандартного устройства ввода, вместо даты и времени создания файла используются текущие дата и время. Можно печатать файлы рядом, каждый в своем столбце, а также управлять многими возможностями форматирования с помощью различных опций. Как обычно, дополнительную информацию вы можете найти на man-странице. Команда nl нумерует строки, что может оказаться полезным при печати файлов. Для нумерации строк можно также использовать команду cat с опцией -n . В листинге 12 показано, как распечатать наш текстовый файл, пронумеровать строки в файле text2 и вывести его на печать вместе с файлом text1. Другой полезной командой для форматирования текста является команда fmt , которая форматирует текст таким образом, чтобы он не выходил за границы полей. Можно объединить несколько коротких строк в одну длинную и наоборот. В листинге 13 мы создали файл text3, используя одну длинную конструкцию из комбинаций символов!#:* (предназначенных для управления историей команд), благодаря чему, напечатанное предложение было сохранено в файле четыре раза. Также мы создали файл text4, содержащий по одному слову в каждой строке. Затем с помощью команды cat мы отобразили содержимое этих файлов в неформатированном виде, включая символ конца строки "$". Наконец, с помощью команды fmt мы отформатировали эти файлы, ограничив максимальное значение длины строки 60 символами. Как обычно, дополнительную информацию вы можете найти на man-странице. Команда sort сортирует входные данные с использованием схемы упорядочивания локали (LC_COLLATE) системы. Команда sort также может объединять уже отсортированные файлы и определять, является ли файл отсортированным или нет. В листинге 14 приведены примеры использования команды sort для сортировки двух текстовых файлов после замены в файле text1 пробелов на символы табуляции. Поскольку сортировка выполняется на основе символьных значений, вы можете удивиться, увидев результаты. К счастью, команда sort может выполнять сортировку не только на основе символьных, но также и на основе числовых значений. Вы можете указать требуемый метод сортировки для всей записи или для каждого поля
. Если вы не указываете разделитель полей, то используются пробелы или символы табуляции. Во втором примере листинга 14 сортировка первого поля выполняется по числовым значениям, а сортировка второго поля – с использованием схемы упорядочивания (в алфавитном порядке). Также показан пример использования опции -u для удаления повторяющихся строк. Заметьте, что в списке все равно присутствуют две строки со словом "apple", поскольку проверка уникальности выполнялась по всем ключам сортировки (в нашем случае это k1n и k2). Подумайте, какие команды нужно изменить или добавить в конвейер в последнем примере, чтобы исключить дублирование слова "apple". Можно управлять удалением повторяющихся строк с помощью другой команды – uniq . В обычном режиме команда uniq работает с отсортированными файлами и удаляет последовательные
повторяющиеся строки из любого файла независимо от того, отсортирован он или нет. Также эта команда может игнорировать заданные поля. В листинге 15 выполняется сортировка наших двух текстовых файлов по второму полю (имя фрукта), после чего удаляются строки, в которых повторяются значения второго поля (т. е. при проверке мы не обращаем внимания на первое поле). В этом примере сортировка выполнялась с использованием схемы упорядочивания, поэтому команда uniq оставила запись "10 apple", а не "1 apple". Вы можете добавить сортировку первого поля по числовым значениями и посмотреть, что изменится в этом случае. Давайте рассмотрим еще три команды, которые работают с полями в текстовых данных. Эти команды особенно полезны при работе с табличными данными. Первая команда cut извлекает поля из текстовых файлов. Символом-разделителем по умолчанию является символ табуляции. В листинге 16 содержится пример, в котором команда cut используется для разделения двух столбцов файла text2, а затем в качестве разделителя выходных данных используется пробел, что является необычным способом преобразования символов табуляции в пробелы. Команда paste вставляет (склеивает) строки из двух или более файлов, размещая их рядом (подобно тому, как команда pr объединяет файлы с помощью опции -m). В листинге 17 показан результат применения этой команды к нашим текстовым файлам. В этом примере показана простейшая операция, тем не менее, команда paste может вставлять данные из одного или нескольких файлов различными способами. Для получения дополнительной информации обратитесь к man-странице. Последняя команда для управления полями – это команда join , которая объединяет файлы на основе совпадения полей. Файл должен быть отсортирован по объединяемому полю. Поскольку файл text2 не отсортирован по числовым значениям, то можно отсортировать его, а затем объединить с помощью команды join две строки с одинаковым значением поля, по которому выполняется объединение (в нашем примере это первое поле, содержащее значение 3). Что же здесь пошло не так? Вспомните материал раздела , в котором говорилось о сортировке на основе числовых и символьных значений. Объединение выполняется по совпадающим символам в соответствии со схемой упорядочивания locale. Объединение не будет выполняться для числовых полей до тех пор, пока все поля не будут иметь одинаковую длину. Мы использовали опцию -j 1 для объединения по первому полю в каждом файле. Для каждого файла можно указать отдельное поле, по которому будет выполняться объединение. Например, можно объединить поле 3 в одном файле с полем 10 другого файла. Давайте создадим еще один файл, text5, выполнив сортировку файла text1 по второму полю (имя фрукта), а затем заменив пробелы на символы табуляции. Если теперь мы отсортируем файл text2 по второму полю и объединим его с файлом text5 по этому же полю, то получим два совпадения (apple и banana). Это объединение показано в листинге 19. Sed (s
tream ed
itor) – это потоковый редактор. Ему посвящено несколько статей Web-сайта developerWorks, а также множество книг (см. раздел ). Sed является чрезвычайно мощным инструментом, а круг решаемых им задач ограничен лишь вашим воображением. Этот небольшой обзор должен пробудить ваш интерес к sed, хотя он не является полным и всесторонним. Как и многие команды для работы с текстом, которые мы здесь рассмотрели, sed может работать как фильтр или принимать входные данные из файла. Вывод осуществляется на стандартное устройство вывода. Sed загружает строки из входных данных в область шаблонов
, применяет к ее содержимому команды редактирования и передает ее на стандартное устройство вывода. Sed может объединять в области шаблонов несколько строк; результат может быть записан в файл, может быть записан частично, а может быть не записан вообще. Для поиска и выборочной замены текста в области шаблонов, а также для определения строк, над которыми необходимо выполнять те или иные команды редактирования, sed использует синтаксис регулярных выражений. Более подробно о регулярных выражениях рассказывается в статье "Поиск в текстовых файлах с помощью регулярных выражений
" (см. ). Временным хранилищем текста служит буфер удержания
. Буфер удержания может заместить собой область шаблонов, может быть добавлен к области шаблонов, а может обмениваться с ней данными. Хотя в sed имеется ограниченное число команд, их использование совместно с регулярными выражениями и буфером удержания открывает безграничные возможности. Набор команд sed обычно называется сценарием sed
. В листинге 20 показаны три простых сценария sed. В первом сценарии используется команда s (substitute – замена) для замены в каждой строке символа "a" в нижнем регистре на этот же символ в верхнем регистре. В первом примере выполняется замена только первого символа "a", поэтому во втором примере мы добавили флаг "g" (global – глобальный), благодаря которому, будет выполняться замена всех найденных вхождений этого символа. В третьем сценарии мы используем команду d (delete – удалить) для удаления строки. В нашем примере мы использовали адрес 2, чтобы показать, что необходимо удалить только строку с этим номером. Мы разделяем команды точкой с запятой (;) и используем глобальную замену символов "a" на "A", как это было сделано во втором примере. Помимо работы с отдельными строками, sed может работать с диапазонами строк. Начало и конец диапазона разделяются запятой (,) и могут определяться в виде номера строки, регулярного выражения или знака доллара ($), означающего конец файла. Зная адрес или диапазон адресов, вы можете сгруппировать несколько команд, заключив их в фигурные скобки { и }; таким образом, эти команды будут работать только с теми строками, которые указаны в диапазоне. В листинге 21 показано два примера глобальной замены, которая применяется только к последним двум строкам нашего файла. Также приведен пример использования опции -e для добавления нескольких команд в сценарий. Сценарии sed можно сохранять в виде файлов. Скорее всего, вы захотите использовать эту возможность для наиболее часто используемых сценариев. Вспомните команду tr , которую мы использовали для изменения пробелов в файле text1 на символы табуляции. Давайте теперь сделаем то же самое с помощью сценария sed, сохраненного в файле. Для создания файла мы используем команду echo . Результаты представлены в листинге 22. Существует множество подобных коротких сценариев; ссылки на некоторые из них вы можете найти в разделе . В нашем последнем примере сначала используется команда = для вывода номеров строк, а затем выполняется фильтрация полученного вывода с помощью sed (в результате мы получим такой же эффект, как от использования команды nl для нумерации строк). В листинге 23 с помощью команды = выводятся номера строк, затем с помощью команды N вторая строка ввода считывается в область шаблонов и, наконец, между двумя строками в области шаблонов удаляется символ новой строки (/n). Не совсем то, что мы хотели получить! Вообще-то, мы ожидали получить выровненный столбец с номерами строк, после которых следуют сами строки файла, отделенные несколькими пробелами. В листинге 24 мы вводим несколько строк с командами (обратите внимание на дополнительное приглашение >). Изучите этот пример и прочитайте его объяснение ниже. Вот, что было сделано в этом примере: Последняя (четвертая) версия редактора sed содержит документацию в формате info и включает множество превосходных примеров. В более старой версии, 3.02, эти возможности отсутствуют. Узнать версию редактора GNU sed можно с помощью команды sed --version . Уже некоторое время поработав в Linux, понабирав команды в командной строке, Мефодий пришёл к выводу, что в общении с оболочкой не помешают кое-какие удобства. Одно из таких удобств - возможность редактировать вводимую строку с помощью клавиши Backspace (удаление последнего символа), « ^W » (удаление слова) и « ^U » (удаление всей строки) - предоставляет сам терминал Linux. Эти команды работают для любого построчного ввода: например, если запустить программу cat без параметров, чтобы та немедленно отображала вводимые с терминала строки. Если по каким-то причинам в строчку на экране влез мусор, можно нажать « ^R » (r
edraw) - система выведет в новой строке содержимое входного буфера. Мефодий не забыл, что cat без параметров следует завершать командой « ^D » (конец ввода). Эту команду, как и предыдущие, интерпретирует при вводе с терминала система. Система же превращает некоторые другие управляющие символы (например, « ^C » или « ^Z ») в сигналы
. В действительности все управляющие символы, интерпретируемые системой, можно перенастроить с помощью команды stty . Полный список того, что можно настраивать, выдаёт команда stty -a: $ stty -a
localhost 38400 baud; rows 30; columns 80; line = 0;
intr = ^C; quit = ^\; erase = ^?; kill = ^U; eof = ^D; eol = Пример 1
. Настройки терминальной линии При виде столь обширных возможностей Мефодий немедленно взялся читать руководство (man stty), однако нашёл в нём не так уж много для себя полезного. Из управляющих символов (строки со второй по четвёртую) интересны « ^S » и « ^Q », с помощью которых можно, соответственно, приостановить и возобновить выдачу на терминал (если текста вывелось уже много, а прочесть его не успеваешь). Можно заметить, что настройка erase (удаление одного символа) соответствует управляющему символу, который возвращается клавишей Backspace именно виртуальной консоли Linux - « ^? ». На многих терминалах клавиша Backspace возвращает другой символ - « ^H ». Если необходимо переопределить
настройку erase , можно воспользоваться командой « stty erase ^H », причём « ^H » (для удобства) разрешено вводить и как два символа: « ^ » и « H ». Наконец, чтобы лишить
передаваемый символ его управляющих функций (если, например, требуется передать программе на ввод символ
с кодом 3 , т. е. « ^C »), непосредственно перед вводом этого символа нужно подать команду « ^V » (lnext): $ cat | hexdump -C
Сейчас нажмём Ctrl+C
$ cat | hexdump -C
Теперь Ctrl+V, Ctrl+C, enter и Ctrl+D^C
00000000 f4 c5 d0 c5 d2 d8 20 43 74 72 6c 2b 56 2c 20 43 |Теперь Ctrl+V, C|
00000010 74 72 6c 2b 43 2c 20 45 6e 74 65 72 20 c9 20 43 |trl+C, enter и C|
00000020 74 72 6c 2b 44 03 0a |trl+D..|
00000027 Пример 2
. Экранирование управляющих символов Здесь Мефодий прервал, как и собирался, работу первого из cat . При этом до hexdump , фильтра, переводящего входной поток в шестнадцатеричное предстваление, дело даже не дошло, потому что cat не успел обработать ни одной строки. Во втором случае « ^C » после « ^V » потеряло управляющий смысл и отобразилось при вводе. С ключом « -C » hexdump выводит также и текстовое предстваление входного потока, заменяя непечатные символы точками. Так на точки были заменены и « ^C » (ASCII-код 03), и возвращаемый Enter символ конца строки (ASCII-код 0a , в десятичном виде - 12). Ни « ^V », ни « ^D » на вход hexdump , конечно, не попали: их, как управляющие, обработала система. Прочие настройки stty относятся к обработке текста при выводе на терминал и вводе с него. Они интересны только в том смысле, что при их изменении работать с комндной оболочкой становится неудобно. Например, настройка echo определяет, будет ли система отображать на экране всё, что вводит пользователь. При включённом echo нажатие любой алфавитно-цифровой клавиши (ввод символа) приводит к тому, что система (устройство типа tty) выведет
этот символ на терминал. Настройка отключается, когда с клавиатуры вводится пароль. При этом трудно отделаться от ощущения, что ввода с клавиатуры не происходит. Ещё хуже обстоит дело с настройками, состоящими из кусков вида « i », « o », « cr » и « nl ». Эти настройки управляют преобразованием при вводе и выводе исторически сложившегося обозначения конца строки двумя символами в один
, принятый в Linux. Может случиться так, что клавиша Enter терминала возвращает как раз неправильный символ конца строки, а преобразование отключено. Тогда вместо Enter следует использовать « ^J » - символ, на самом деле соответствующий концу строки. Во всех случаях, когда терминал находится в непонятном состоянии - не реагирует на Enter , не показывает ввода, не удаляет символов, выводит текст «ступеньками» и т. п., рекомендуется «лечить» настройки терминала с помощью stty sane - специальной формы stty , сбрасывающей настройки терминала в некоторе пригодное к работе состояние. Если непонятное состояние терминала возникло однократно, например, после аварийного завершения экранной программы (редактора vim или оболочки mc), то можно воспользоваться командой reset . Она заново настраивает терминал в полном соответствии
с системной конфигурацией (указанной в файле /etc/inittab , см. лекцию Этапы загрузки системы) и terminfo . Если терминал ведёт себя странно, последовательность « ^J stty sane^J » может его вылечить! Даже не изучая специально возможностей командной оболочки, Мефодий активно использовал некоторые из них, не доступные при вводе текста большинству
утилит (в частности, ни cat , ни hexdump). Речь идёт о клавишах Стрелка влево и Стрелка вправо , с помощью которых можно перемещать курсор по командной строке, и клавише Del , удаляющей символ под
курсором, а не позади него. В лекции Терминал и командная строка он уже убедился, что эти команды работают в bash , но не работают для cat . Более того, для простого командного интерпретатора - sh - они тоже не работают. Следовательно, возможности редактора командной строки специфичны для разных командных оболочек. Однако самые необходимые команды редактирования поддерживаются во всех разновидностях shell сходным образом. По словам Гуревича «во всех видах Linux обязательно есть bash , а если ты достаточно опытен, чтобы устанавливать и настраивать пакеты, можешь установить zsh , у него возможностей больше, чем может понадобиться одному человеку». Поэтому Мефодий занялся изучением документации по bash , что оказалось делом непростым, ибо в bash.info он насчитал более восьми с половиной тысяч строк. Даже про редактирование командной строки написано столько, что за один раз прочесть трудно. Попытка «наскоком» узнать всё про работу в командной строке принесла некоторую пользу. Во-первых, перемещаться в командной строке можно не только по одному символу вперёд и назад, но и по словам: команды ESCF/ESCB или Alt+F/Alt+B соответственно (от f
orward и b
ckward), работают также клавиши &home& и &end& , или, что то же самое, « ^A » и « ^E ». А во-вторых, помимо работы с одной командной строкой, существует ещё немало других удобств, о которых и пойдёт речь в этой лекции. Двумя другими клавишами со стрелками - вверх и вниз - Мефодий тоже активно пользовался, не подозрвая, что задействует этим весьма мощный механизм bash - работу с историей команд
. Все команды, набранные пользователем, bash запоминает и позволяет обращаться к ним впоследствии. По стрелке вверх (можно использовать и « ^P », p
revious), список поданных команд «прокручивается» от последней к первой, а по стрелке вниз (« ^N », n
ext) - обратно. Соответствующая команда отображается в командной строке как только что набранная, её можно отредактировать и подать оболочке (подгонять курсор к концу строки при этом не обязательно). Если необходимо добыть из истории какую-то давнюю команду, проще не гонять список истории стрелками, а поискать
в ней с помощью команды « ^R » (r
everse search). При этом выводится подсказка специального вида («(reverse-i-search)»), подстрока поиска (окружённая символами ` и ") и последняя из команд в истории, в которой эта подстрока присутствует: $
^R | (reverse-i-search)`":
i | (reverse-i-search)`i": ls i
n | (reverse-i-search)`in": info
f | (reverse-i-search)`inf": info
o | (reverse-i-search)`info": info
^R | (reverse-i-search)`info": man info
^R | (reverse-i-search)`info": info "(bash.info.bz2)Commands For History" Пример 3
. Поиск по истории команд Пример представляет символы вводимые Мефодием (в левой части до « | ») и содержимое последней строки терминала. Это «кадры» работы с одной и той же строкой, показывающие, как она меняется при наборе. Набрав «info», Мефодий продолжил поиск этой подстроки, повторяя « ^R » до тех пор, пока не наткнулся на нужную ему команду, содержащую подстроку « info ». Осталось только передать её bash с помощью Enter . Чтобы история команд могла сохраняться между
сеансами работы пользователя, bash записывает её в файл.bash_history , находящийся в домашнем каталоге пользователя. Делается это в момент завершения
оболочки: накопленная за время работы история дописывается в конец этого файла. При следующем запуске bash считывает.bash_history целиком. История хранится не вечно, количество запоминаемых команд в.bash_history ограничено (обычно 500 командами, но это можно и перенастроить). Поиск по истории - удобное средство: длинную командную строку можно не набирать целиком, а выискать и использовать. Однако давнюю
команду придётся добывать с помощью нескольких « ^R » - а можно и совсем не доискаться, если она уже выбыла оттуда. Для того, чтобы оперативно заменять короткие команды длинными, стоит воспользоваться сокращениями
(aliases). В конфигурационных файлах командного интерпретатора пользователя обычно уже определено несколько сокращений, список которых можно посмотреть с помощью команды alias без параметров: $ alias
alias cd..="cd .."
alias cp="cp -i"
alias l="ls -lapt"
alias ll="ls -laptc"
alias ls="ls --color=auto"
alias md="mkdir"
alias mv="mv -i"
alias rd="rmdir"
alias rm="rm -i" Пример 4
. Просмотр заранее определённых сокращений С сокращениями Мефодий уже сталкивался в лекции Права доступа , где команда ls отказалась работать в согласии с теорией. Выяснилось, что по команде ls вместо утилиты /bin/ls bash запускает собственную команду-сокращение, превращающееся в команду ls --color=auto . Повторно
появившуюся в команде подстроку « ls » интерпретатор уже не обрабатывает, во избежание вечного цикла. Например, команда ls -al превращается в результате в ls --color=auto -al . Точно так же любая команда, начинающаяся с rm , превращается в rm -i (i
nteractive), что Мефодия крайне раздражает, потому что ни одно удаление не обходится без вопросов в стиле «rm: удалить обычный файл ` файл "?». $ unalias cp rm mv
$ alias pd=pushd
$ alias pp=popd
$ pd /bin
/bin ~
$ pd /usr/share/doc
/usr/share/doc /bin ~
$ cd /var/tmp
$ dirs
/var/tmp /bin ~
$ pp
/bin ~
$ pp
~
$ pp
-bash: popd: directory stack empty Пример 5
. Использование сокращений и pushd/popd От надоедливого « -i » Мефодий избавился с помощью команды unalias , а заодно ввёл сокращения для полюбившихся ему команд bash - pushd и popd . Эти команды, подобно cd , меняют текущий каталог. Они названы по аналогии с операциями работы со стеком - push и pop . Разница состоит в том, что pushd все каталоги, которые пользователь делает текущими, запоминает в особом списке (стеке). Команда popd удаляет последний элемент этого стека, и делает текущим каталогом предпоследний. Обе команды вдобавок выводят содержимое стека каталогов (то же самое делает и команда dirs). Команда cd в bash также работает со стеком каталогов: она заменяет
его последний элемент новым. Команда-сокращение
Внутренняя команда shell, задаваемая пользователем. Обычно заменяет одну более длинную команду, которая часто используется при работе в командной строке. Сокращения не наследуются с окружением.
Сокращения позволяют быстро набирать команды
, однако никак не затрагивают имён файлов
, которые чаще всего и оказываются параметрами этих команд. Бывает, что набранной строки - пути к файлу и нескольких первых букв его имени - достаточно для однозначного
указания на этот файл, потому что по введённому пути болшьше файлов, чьё имя начинается на эти буквы, просто нет. Чтобы не дописывать оставшиеся буквы (а имена файлов в Linux могут быть весьма длинными), Гуревич посоветовал Мефодию нажать клавишу Tab . И - о чудо! - bash сам достроил начало имени файла до целого (снова воспользуемся методом «кадров»): $ ls -al /bin/base
Tab | $ ls -al /bin/basename
-rwxr-xr-x 1 root root 12520 Июн 3 18:29 /bin/basename
$ base
Tab | $ basename
Tab | $ basename ex
Tab | $ basename examples/
Tab | $ basename examples/-filename-with-
-filename-with- Пример 6
. Использование достраивания Дальше - больше. Оказывается, и имя команды можно вводить не целиком: оболочка догадается достроить набираемое слово именно до команды, раз уж это слово стоит в начале командной строки. Таким образом, команду basename examples/-filename-with- Мефодий набрал за восемь нажатий на клавиатуру (« base » и четыре Tab)! Ему не пришлось вводить начало имени файла в каталоге examples , потому что файл там был всего один. Выполняя достраивание (completion), bash может вывести не всю строку, а только ту её часть, относительно которой у него нет сомнений. Если дальнейшее достраиване может пойти несколькими
путями, то однократное нажатие Tab приведёт к тому, что bash растерянно пискнет, а повторное - к выводу под
командной строкой списка всех возможных вариантов. Все терминалы должны уметь выдавать звуковой сигнал при выводе управляющего символа « ^G ». Для этого не нужно запускать никаких дополнительных программ: «настоящие» терминалы имеют встроенный динамик, а виртуальные консоли обычно пользуются системным («пищалкой»). В крайнем случае разрешается привлекать внимание пользователя другими способами: например, эмулятор терминала screen пишет в служебной строке «wuff-wuff» («гав-гав»). В этом случае надо подсказать командной оболочке продолжение: дописать несколько символов, определяющих, по какому пути пойдёт достраивание, и снова нажать Tab . Поиск ключевого слова «completion» по документации bash выдал так много информации, что Мефодий обратился к Гуревичу за помощью. Однако тот ответил, что не использует bash , и поэтому не в состоянии объяснять тонкости его нстройки. Если в bash - несколько типов достраивания (по именам файлов, по именам команд и т. п.), то в zsh их сколько угодно
: существует способ запрограммировать любой алгоритм достраивания и задать шаблон командной строки, в которой именно этот способ будет применяться. Если ваша клавиатура размечена под латиницу или кириллицу, а вам приходится набирать тексты на другом языке, особенно, используя сложные, неалфавитные письменности, то данная заметка о системах ввода в Linux (упрощенно "клавиатурных раскладках") может вас заинтересовать. Заранее прошу прощение за нечёткую терминологию и не претендую на исчерпывающее техническое описание. Основная задача статьи - описание возможностей, а не реализация. Основным методом ввода символов (input method, IM) в Linux является XKB, он установлен по умолчанию и активируется сразу после установки операционной системы. XKB предназначен для работы с алфавитными письменностями, и не может обслуживать комплексные письменности типа китайских иероглифов или силлабариев Индии и Африки. Систему можно настроить на работу с не более чем 4 раскладками. Последнее ограничение можно обойти, повесив на горячие клавиши вызов команды с нужной комбинацией параметров для каждого языка. Если требуется большая гибкость, то следует перейти к фреймворкам (input method framework). Основные представители подобных систем в Linux: IBus, SCIM, Fcitx. Сам по себе фреймворк текст вводить не умеет, а различные письменности должны подключаться в виде плагинов (engines). Из опыта использования IBus и Fcitx могу сказать, что обе системы поддерживают примерно равное количество плагинов. Зачастую, это могут быть практически одни и те же плагины. Например, метод ввода Pinyin для китайского языка реализован в виде самостоятельной библиотеки libpinyin и при подключении через IBus или Fcitx предоставляет идентичные возможности. Во-первых, IBus способен прозрачно использовать xkb
и все его возможности. Единственная проблема в том, что IBus не умеет динамически генерировать конфигурации XKB. Наиболее популярные из них заранее прописаны в файле /usr/share/ibus/component/simple.xml , который можно изменять и дополнять по необходимости. (При обновлении IBus файл будет заменён на стандартный.) Например, русская раскладка описана следующим образом: В дополнение к layout можно указать layout_variant , остальные параметры setxkbmap недоступны, в том числе и известная типографская раскладка Ильи Бирмана, которая задаётся в xkb через аргумент misc:typo . Чтобы обойти это ограничение или просто создать раскладку под свои задачи, её нужно полностью описать. Для этого, в папке /usr/share/X11/xkb/symbols нужно создать файл custom (если дополнять существующие файлы, то при обновлении системы они будут затёрты) и задать конфигурацию раскладки. Например, русская с дополнениями Ильи Бирмана: Где строки include собирают конфигурацию из готовых шаблонов. Соответственно, из файла "ru" берётся вариант русской раскладки "winkeys". Потом дополняется раскладкой "base" из файла "typo" и задаётся переключатель третьего слоя AltGr (см. файл "level3"), что аналогично команде: При желании, можно внести собственные изменения. В приведённом выше примере знак ударения "U+0301" (Combining Acute Accent) вынесен на сочетание AltGr+~. Позиции, в которых указано NoSymbol , используют определения из предыдущих шаблонов: "ё" и "Ё" из "winkeys", "≈" из "typo": Где custom - имя файла из папки /usr/share/X11/xkb/symbols , а ru-typo указывает на содержащуюся в нём раскладку. Дополнительная раскладка us указана, чтобы корректно работали горячие клавиши (Ctrl+С, Ctrl+V и т.п.). После перезагрузки IBus (ibus restart) в настройках появится новая раскладка "Russian (with Typo)". Второй метод ввода - m17n
. Это довольно богатая библиотека клавиатурных раскладок для разнообразных письменностей. IBus имеет собственный схожий метод ввода ibus-table
, который описан как обладающий "чуть меньшими возможностями". Мне приходилось использовать последний для создания раскладки с однозначным соответствием между латинскими буквами и буквами требуемого алфавита без задействования сложно логики, поэтому я не могу судить, какая из двух систем более функциональная и выразительная - описание раскладки в формате m17n или ibus-table. Метод ibus-table включает в себя любопытную раскладку "LaTeX" для ввода символов в соответствующей нотации: " \Delta " для "Δ", " \ge " для "≥" и т.д. Следующий из универсальных методов ввода - KMFL
. Это метода ввода Keyman для Windows. Не очень распространённый IM, который поддерживает самые редкие письменности. В отличие от оригинального Keyman, с заявленной возможностью печатать на более чем 1000 письменностях, KMFL не настолько развит, но тоже может быть полезен. Формат описания раскладок текстовый, существует программа для их создания под Ms Windows. Я использую раскладку EuroLatin, в которой текст " 2//3 " преобразуется в дробь "⅔", а последовательность " -a " превращается в макрон "ā". Напоминает Compose key в xkb, но не требует отдельного модификатора - KMFL сам распознает последовательности во время набора. Остальные методы ввода специализируются на отдельных письменностях: "ibus-libpinyin" для китайского языка, "ibus-unikey" для вьетнамского и т.д. Настройки этих плагинов также находятся в /usr/share/ibus/component/ . В соответствующих файлах может потребоваться задать базовую раскладку клавиатуры, иначе при переключении с нелатинской раскладки они будут нерабочими. Например, в libpinyin.xml нужно найти параметр "layout" и вписать "us" для клавиатуры QWERTY или "fr" для AZERTY и т.п. Большую часть времени я работаю с языковыми парами: русский-английский, китайский-испанский и т.п. Поэтому предпочитаю иметь одну горячую клавишу для переключения между двумя последними раскладками (CapsLock), а сами раскладки переключаются по отдельным горячим клавишам (Win + 1…9 на цифровом блоке). Таким образом, сначала я задаю рабочие раскладки, Win+1 (en) и Win+2 (ru), а далее переключаюсь между ними по CapsLock (en <-> ru). В IBus можно задать две горячих клавиши: одна для циклического переключения по списку раскладок, вторая для последних двух раскладок. Так же можно выбирать нужную раскладку через консоль и, соответственно, назначить скрипт на горячую клавишу. Замечу, что переназначить CapsLock с помощью xmodmap не получится, так как IBus сбрасывает подобные настройки. Поэтому я предпочитаю через udev глобально переопределять CapsLock как F14 (файл /etc/udev/hwdb.d/90-custom-keyboard.hwdb): И использовать уже F14 как горячую клавишу в IBus. По моему опыту это обеспечивает наиболее стабильную конфигурацию. Подробнее о настройке udev см. в конце статьи. Промышленно выпускаются клавиатуры, размеченные под определённую письменность, лишь для языков с большим количеством пользователей - например, для русского (ЙЦУКЕН). Ни в Армении, ни в Грузии вы не сможете купить клавиатуру с клавишами, подписанными буквами национальных алфавитов. Аналогично, в Казахстане и Узбекистане используют русско-английские клавиатуры и вынуждены учить, где располагаются буквы, не входящие в стандартную латиницу или кириллицу. Если вы осваиваете новую раскладку, советую воспользоваться виртуальной клавиатурой. Мне нравитcя Onboard , потому что она самостоятельно подстраивается под активную раскладку и обновляется при переключении на другую. Но это работает только с xkb (также при использовании xkb через IBus). Onboard очень удобна для тестирования раскладок xkb и позволяет посмотреть назначенные символы на всех слоях (AltGr и т.п.). Не все программы корректно поддерживают языковые фреймворки. В частности, Sublime Text 3 работает лишь со SCIM, а используя IBus, независимо от выбранной раскладки, будет печатать исключительно латинские буквы. Я довольно давно использую IBus, а другие системы знаю очень поверхностно. По отзывам в интернете, Fctix описывается как более функциональный и лучше адаптированный для ввода китайского текста. В любом случае, при работе с китайскими текстами IBus меня полностью устраивает и различия должны быть непринципиальными. Последний раз, когда мне приходилось использовать Fctix (2 года назад), этот фреймворк не позволял переключать раскладки, если курсор не находится в текстовом поле. Надеюсь, к настоящему моменту эту недоработку исправили. Ещё одно подспорье для работы с разнообразными письменностями - силиконовые накладки на клавиатуру. Китайские интернет-маркеты предлагают накладки (保护膜 или 键盘膜) для Apple Magic Keyboard под самые различные письменности. Пример некитайского дистрибьютора . Но учтите, что выпускалось три поколения Apple Magic (и каждая в модификациях для США, Европы и Японии), а китайские реплики отличаются линейными размерами и расположением клавиш. Временами, я сожалению, что не существует единого стандарта на компьютерные клавиатуры. Краткая справка о преобразовании сигнала о нажатии клавиши
Цифровой код нажатой клавиши несколько раз меняет своё значение. Из приведённой последовательности видно, что переназначение клавиш на этапе scancode
> keycode
предпочтительнее, так как это не вызывает пересечений с KXB. Инструкция по настройке udev
Трансляция scancode
в keycode
производится для каждого устройства ввода независимо, поэтому сперва требуется узнать уникальный идентификатор клавиатуры (на самом деле evdev работает также с большим классом периферийных устройств, имеющих кнопки - от мышек до принтеров и веб-камер). Пользователи Arch Linux могут воспользоваться следующим скриптом (для других дистрибутивов, возможно, потребуется корректировка путей): Одно и то же устройство может быть представлено в системе в нескольких экземплярах под разными именами, но идентификатор будет одинаковым. Например, моя клавиатура определяется как два устройства: Примечание: идентификатор можно сокращать (например, до b0003v1a2cp0e24*), что бывает полезно при создании единых правил для серии однотипных моделей. Звёздочка “*” здесь играет роль символа подстановки (wildcard). Теперь нужно создать файл 90-custom-keyboard.hwdb в /etc/udev/hwdb.d/ со следующим содержанием (образцы см. в /usr/lib/udev/hwdb.d/60-keyboard.hwdb): Строка KEYBOARD_KEY начинается с пробела, это важно. Обновите конфигурацию: В последующем, при перезагрузке или переподключении устройства конфигурация будет обновляться автоматически. Переназначение клавиш задаётся парами KEYBOARD_KEY_

Использование тоннелей


Выводы
Текстовые потоки и фильтры
Серия контента:
Краткий обзор
Об этой серии
Необходимые условия
Фильтрация текста
Как связаться с Яном
Потоки
Конвейеризация с использованием оператора |
Листинг 1. Передача вывода команды echo на вход команды sort
$ echo -e "apple\npear\nbanana"|sort
apple
banana
pear
Перенаправление вывода с помощью оператора >
Листинг 2. Перенаправление вывода команды в файл
$ mkdir lpi103-2
$ cd lpi103-2
$ echo -e "1 apple\n2 pear\n3 banana" > text1
Команды cat, od и split
Листинг 3. Вывод содержимого файла с помощью команды cat
$ cat text1
1 apple
2 pear
3 banana
Листинг 4. Создание текстового файла с помощью команды cat
$ cat >text2
9 plum
3 banana
10 apple
Другие простые фильтры
tac text2 text1
Листинг 5. Объединение двух файлов с помощью команды cat
$ cat text*
1 apple
2 pear
3 banana
9 plum
3 banana
10 apple
Листинг 6. Дампы файлов, созданные с помощью команды od
$ od text2
0000000 004471 066160 066565 031412 061011 067141 067141 005141
0000020 030061 060411 070160 062554 000012
0000031
$ od -A d -t c text2
0000000 9 \t p l u m \n 3 \t b a n a n a \n
0000016 1 0 \t a p p l e \n
0000025
$ od -A n -t a text2
9 ht p l u m nl 3 ht b a n a n a nl
1 0 ht a p p l e nl
Листинг 7. Разделение и восстановление файлов с помощью команд split и cat
$ split -l 2 text1
$ split -b 17 text2 y
$ cat yaa
9 plum
3 banana
1$ cat yab
0 apple
$ cat y* x*
9 plum
3 banana
10 apple
1 apple
2 pear
3 banana
Команды wc, head и tail
Листинг 8. Использование команды wc для работы с текстовыми файлами
$ ls -l text*
-rw-rw-r--. 1 ian ian 24 2009-08-11 14:02 text1
-rw-rw-r--. 1 ian ian 25 2009-08-11 14:27 text2
$ wc text*
3 6 24 text1
3 6 25 text2
6 12 49 total
Листинг 9. Использование команд wc, head и tail для вывода сообщений о загрузке
$ dmesg|wc
791 5554 40186
$ dmesg | tail
input: HID 04b3:310b as /devices/pci0000:00/0000:00:1a.0/usb3/3-2/3-2.4/3-2.4:1.0/input/i
nput12
generic-usb 0003:04B3:310B.0009: input,hidraw1: USB HID v1.00 Mouse on us
b-0000:00:1a.0-2.4/input0
usb 3-2.4: USB disconnect, address 11
usb 3-2.4: new low speed USB device using uhci_hcd and address 12
usb 3-2.4: New USB device found, idVendor=04b3, idProduct=310b
usb 3-2.4: New USB device strings: Mfr=0, Product=0, SerialNumber=0
usb 3-2.4: configuration #1 chosen from 1 choice
input: HID 04b3:310b as /devices/pci0000:00/0000:00:1a.0/usb3/3-2/3-2.4/3-2.4:1.0/input/i
nput13
generic-usb 0003:04B3:310B.000A: input,hidraw1: USB HID v1.00 Mouse on us
b-0000:00:1a.0-2.4/input0
usb 3-2.4: USB disconnect, address 12
$ dmesg | tail -n15 | head -n 6
usb 3-2.4: USB disconnect, address 10
usb 3-2.4: new low speed USB device using uhci_hcd and address 11
usb 3-2.4: New USB device found, idVendor=04b3, idProduct=310b
usb 3-2.4: New USB device strings: Mfr=0, Product=0, SerialNumber=0
usb 3-2.4: configuration #1 chosen from 1 choice
input: HID 04b3:310b as /devices/pci0000:00/0000:00:1a.0/usb3/3-2/3-2.4/3-2.4:1.0/input/i
nput12
Команды expand, unexpand и tr
Листинг 10. Использование команд expand и unexpand
$ expand -t 1 text2
9 plum
3 banana
10 apple
$ expand -t8 text2|unexpand -a -t2|expand -t3
9 plum
3 banana
10 apple
Листинг 11. Использование команды tr
$ cat text1 |tr " " "\t"|cat - text2
1 apple
2 pear
3 banana
9 plum
3 banana
10 apple
cat text1 |tr " " "\t" | od -tc
Команды Pr, nl и fmt
Листинг 12. Нумерация строк и форматирование перед печатью
$ pr text1 | head
2009-08-11 14:02 text1 Page 1
1 apple
2 pear
3 banana
$ nl text2 | pr -m - text1 | head
2009-08-11 15:36 Page 1
1 9 plum 1 apple
2 3 banana 2 pear
3 10 apple 3 banana
Листинг 13. Форматирование с указанием максимальной длины строки
$ echo "This is a sentence. " !#:* !#:1->text3
echo "This is a sentence. " "This is a sentence. " "This is a sentence. ">text3
$ echo -e "This\nis\nanother\nsentence.">text4
$ cat -et text3 text4
This is a sentence. This is a sentence. This is a sentence. $
This$
is$
another$
sentence.$
$ fmt -w 60 text3 text4
This is a sentence. This is a sentence. This is a
sentence.
This is another sentence.
Команды sort и uniq
Листинг 14. Сортировка по символьным и числовым значениям
$ cat text1 | tr " " "\t" | sort - text2
10 apple
1 apple
2 pear
3 banana
3 banana
9 plum
$ cat text1|tr " " "\t"|sort -u -k1n -k2 - text2
1 apple
2 pear
3 banana
9 plum
10 apple
Листинг 15. Использование команды uniq
$ cat text1|tr " " "\t"|sort -k2 - text2|uniq -f1
10 apple
3 banana
2 pear
9 plum
Команды cut, paste и join
Листинг 16. Использование команды cut
$ cut -f1-2 --output-delimiter=" " text2
9 plum
3 banana
10 apple
Листинг 17. Склеивание файлов
$ paste text1 text2
1 apple 9 plum
2 pear 3 banana
3 banana 10 apple
Листинг 18. Объединение файлов по совпадающим полям
$ sort -n text2|join -j 1 text1 -
3 banana banana
join: file 2 is not in sorted order
Листинг 19. Объединение файлов по совпадающим полям
$ sort -k2 text1|tr " " "\t">text5
$ sort -k2 text2 | join -1 2 -2 2 text5 -
apple 1 10
banana 3 3
Редактор Sed
Листинг 20. Первые шаги по работе со сценариями sed
$ sed "s/a/A/" text1
1 Apple
2 peAr
3 bAnana
$ sed "s/a/A/g" text1
1 Apple
2 peAr
3 bAnAnA
$ sed "2d;$s/a/A/g" text1
1 apple
3 bAnAnA
Листинг 21. Адреса в sed
$ sed -e "2,${" -e "s/a/A/g" -e "}" text1
1 apple
2 peAr
3 bAnAnA
$ sed -e "/pear/,/bana/{" -e "s/a/A/g" -e "}" text1
1 apple
2 peAr
3 bAnAnA
Листинг 22. Короткая программа sed
$ echo -e "s/ /\t/g">sedtab
$ cat sedtab
s/ / /g
$ sed -f sedtab text1
1 apple
2 pear
3 banana
Листинг 23. Нумерация строк с помощью sed
$ sed "=" text2
1
9 plum
2
3 banana
3
10 apple
$ sed "=" text2|sed "N;s/\n//"
19 plum
23 banana
310 apple
Листинг 24. Нумерация строк с помощью sed, второй подход
$ cat text1 text2 text1 text2>text6
$ ht=$(echo -en "\t")
$ sed "=" text6|sed "N
> s/^/ /
> s/^.*\(......\)\n/\1$ht/"
1 1 apple
2 2 pear
3 3 banana
4 9 plum
5 3 banana
6 10 apple
7 1 apple
8 2 pear
9 3 banana
10 9 plum
11 3 banana
12 10 apple
Редактирование командной строки
История команд
Сокращения
Достраивание
Методы ввода
partial alphanumeric_keys
xkb_symbols "ru-typo" {
include "ru(winkeys)"
include "typo(base)"
include "level3(ralt_switch)"
// 1th keyboard row
key
setxkbmap -layout ru -variant winkeys -option lv3:ralt_switch,misc:typo
key
Переключение раскладок
evdev:input:b0003v1A2Cp0E24* # my keyboard id
KEYBOARD_KEY_70039=f14 # bind capslock to f14
Виртуальная клавиатура
Заключение
#!/bin/sh
for DEVICE in /dev/input/by-id/*; do
echo $(basename $DEVICE)
DEVID=$(basename $(readlink $DEVICE))
printf "evdev:input:b%sv%sp%se%s*\n\n" \
`cat /sys/class/input/$DEVID/device/id/bustype` \
`cat /sys/class/input/$DEVID/device/id/vendor` \
`cat /sys/class/input/$DEVID/device/id/product` \
`cat /sys/class/input/$DEVID/device/id/version`
done
usb-SEM_USB_Keyboard-event-if01
evdev:input:b0003v1a2cp0e24e0110*
usb-SEM_USB_Keyboard-event-kbd
evdev:input:b0003v1a2cp0e24e0110*
evdev:input:b0003v5c0ap0003e0110* # ваш идентификатор
KEYBOARD_KEY_70039=f14 # переназначение клавиши
sudo udevadm hwdb --update && udevadm trigger






