Robots.txt - это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
Яндекс поддерживает следующие директивы:
| Директива | Что делает |
|---|---|
| User-agent * | |
| Disallow | |
| Sitemap | |
| Clean-param | |
| Allow | |
| Crawl-delay |
| Директива | Что делает |
|---|---|
| User-agent * | Указывает на робота, для которого действуют перечисленные в robots.txt правила. |
| Disallow | Запрещает индексирование разделов или отдельных страниц сайта. |
| Sitemap | Указывает путь к файлу Sitemap , который размещен на сайте. |
| Clean-param | Указывает роботу, что URL страницы содержит параметры (например, UTM-метки), которые не нужно учитывать при индексировании. |
| Allow | Разрешает индексирование разделов или отдельных страниц сайта. |
| Crawl-delay | Задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. |
* Обязательная директива.
Наиболее часто вам могут понадобиться директивы Disallow, Sitemap и Clean-param. Например:
User-agent: * #указываем, для каких роботов установлены директивы\nDisallow: /bin/ # запрещает ссылки из \"Корзины с товарами\".\nDisallow: /search/ # запрещает ссылки страниц встроенного на сайте поиска\nDisallow: /admin/ # запрещает ссылки из панели администратора\nSitemap: http://example.com/sitemap # указываем роботу на файл sitemap для сайта\nClean-param: ref /some_dir/get_book.pl
Роботы других поисковых систем и сервисов могут иначе интерпретировать эти директивы.
Примечание. Робот учитывает регистр в написании подстрок (имя или путь до файла, имя робота) и не учитывает регистр в названиях директив.
Использование кириллицы
Использование кириллицы запрещено в файле robots.txt и HTTP-заголовках сервера.
Для указания имен доменов используйте Punycode . Адреса страниц указывайте в кодировке, соответствующей кодировке текущей структуры сайта.
Пример файла robots.txt :
#Неверно:\nUser-agent: Yandex\nDisallow: /корзина\n\n#Верно:\nUser-agent: Yandex\nDisallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0
Как создать robots.txt
Вопросы и ответы
В Яндекс.Вебмастере на странице «Диагностика сайта» возникает ошибка «Сервер отвечает редиректом на запрос /robots.txt»
Чтобы файл robots.txt учитывался роботом, он должен находиться в корневом каталоге сайта и отвечать кодом HTTP 200. Индексирующий робот не поддерживает использование файлов, расположенных на других сайтах.
Проверить ответ сервера и доступность файла robots.txt для робота можно с помощью инструмента Проверка ответа сервера .
Если ваш robots.txt выполняет перенаправление на другой файл robots.txt (например, при переезде сайта), добавьте сайт, который является целью перенаправления, в Яндекс.Вебмастер и подтвердите права на управление сайтом.
Поисковые роботы - краулеры начинают знакомство с сайтом с чтения файла robots.txt. В нем содержится вся важная для них информация. Владельцам сайтов следует создать и периодически проводить анализ robots.txt. От корректности его работы зависит скорость индексации страниц и место в поисковой выдачи.
Он не является обязательным элементом сайта, но его наличие желательно, потому что с его помощью владельцы сайта управляют поисковыми роботами. Задавайте разные уровни доступа к сайту, запрет на индексацию всего сайта, отдельных страниц, разделов или файлов. Для ресурсов с высокой посещаемостью ограничивайте время индексации и запрещайте доступ роботов, которые не относятся к основным поисковым системам. Это уменьшит нагрузку на сервер.
Создание. Создают файл в текстовом редакторе Notepad или подобных. Следите за тем, чтобы размер файла не превышал 32 КБ. Выбирайте для файла кодировку ASCII или UTF-8. Учтите, что файл должен быть единственным. Если сайт создан на CMS, то он будет генерироваться автоматически.
Разместите созданный файл в корневой директории сайта рядом с основным файлом index.html. Для этого используют FTP доступ. Если сайт сделан на CMS, то с файлом работают через административную панель. Когда файл создан и работает корректно, он доступен в браузере.
При отсутствии robots.txt поисковые роботы собирают всю информацию, относящуюся к сайту. Не удивляйтесь, когда увидите в выдаче незаполненные страницы или служебную информацию. Определите, какие разделы сайта будут доступны пользователям, остальные - закройте от индексации.
Проверка. Периодически проверяйте, все ли работает корректно. Если краулер не получает ответ 200 ОК, то он автоматически считает, что файла нет, и сайт открыт для индексации полностью. Коды ошибок бывают такими:
3хх - ответы переадресации. Робота направляют на другую страницу или на главную. Создавайте до пяти переадресаций на одной странице. Если их будет больше, робот пометит такую страницу как ошибку 404. То же самое относится и к переадресации по принципу бесконечного цикла;
4хх - ответы ошибок сайта. Если краулер получает от файла robots.txt 400-ую ошибку, то делается вывод, что файла нет и весь контент доступен. Это также относится к ошибкам 401 и 403;
5хх - ответы ошибок сервера. Краулер будет «стучаться», пока не получит ответ, отличный от 500-го.
Правила создания
Начинаем с приветствия. Каждый файл должен начинаться с приветствия User-agent. С его помощью поисковики определят уровень открытости.
| Код | Значение |
| User-agent: * | Доступно всем |
| User-agent: Yandex | Доступно роботу Яндекс |
| User-agent: Googlebot | Доступно роботу Google |
| User-agent: Mail.ru | Доступно роботу Mail.ru |
Добавляем отдельные директивы под роботов. При необходимости добавляйте директивы для специализированных поисковых ботов Яндекса.
Однако в этом случае директивы * и Yandex не будут учитываться.
У Google собственные боты:
Сначала запрещаем, потом разрешаем. Оперируйте двумя директивами: Allow - разрешаю, Disallow - запрещаю. Обязательно укажите директиву disallow, даже если доступ разрешен ко всему сайту. Такая директива является обязательной. В случае ее отсутствия краулер может не верно прочитать остальную информацию. Если на сайте нет закрытого контента, оставьте директиву пустой.
Работайте с разными уровнями. В файле можно задать настройки на четырех уровнях: сайта, страницы, папки и типа контента. Допустим, вы хотите закрыть изображения от индексации. Это можно сделать на уровне:
- папки - disallow: /images/
- типа контента - disallow: /*.jpg
| Нет | Да |
| Disallow: Yandex |
User-agent: Yandex Disallow: / |
| Disallow: /css/ /images/ |
Disallow: /css/ Disallow: /images/ |
Пишите с учетом регистра.
Имя файла укажите строчными буквами. Яндекс в пояснительной документации указывает, что для его ботов регистр не важен, но Google просит соблюдать регистр. Также вероятна ошибка в названиях файлов и папок, в которых учитывается регистр.
Укажите 301 редирект на главное зеркало сайта . Раньше для этого использовалась директива Host, но с марта 2018 г. она больше не нужна. Если она уже прописана в файле robots.txt, удалите или оставьте ее на свое усмотрение; роботы игнорируют эту директиву.
Для указания главного зеркала проставьте 301 редирект на каждую страницу сайта. Если редиректа стоят не будет, поисковик самостоятельно определит, какое зеркало считать главным. Чтобы исправить зеркало сайта, просто укажите постраничный 301 редирект и подождите несколько дней.
Пропишите директиву Sitemap (карту сайта). Файлы sitemap.xml и robots.txt дополняют друг друга. Проверьте, чтобы:
- файлы не противоречили друг другу;
- страницы были исключены из обоих файлов;
- страницы были разрешены в обоих файлах.
Указывайте комментарии через символ #. Все, что написано после него, краулер игнорирует.
Проверка файла
Проводите анализ robots.txt с помощью инструментов для разработчиков: через Яндекс.Вебмастер и Google Robots Testing Tool. Обратите внимание, что Яндекс и Google проверяют только соответствие файла собственным требованиям. Если для Яндекса файл корректный, это не значит, что он будет корректным для роботов Google, поэтому проверяйте в обеих системах.
Если вы найдете ошибки и исправите robots.txt, краулеры не считают изменения мгновенно. Обычно переобход страниц осуществляется один раз в день, но часто занимает гораздо большее время. Проверьте через неделю файл, чтобы убедиться, что поисковики используют новую версию.
Проверка в Яндекс.Вебмастере
Сначала подтвердите права на сайт. После этого он появится в панели Вебмастера. Введите название сайта в поле и нажмите проверить. Внизу станет доступен результат проверки.
Дополнительно проверяйте отдельные страницы. Для этого введите адреса страниц и нажмите «проверить».
Проверка в Google Robots Testing Tool
Позволяет проверять и редактировать файл в административной панели. Выдает сообщение о логических и синтаксических ошибках. Исправляйте текст файла прямо в редакторе Google. Но обратите внимание, что изменения не сохраняются автоматически. После исправления robots.txt скопируйте код из веб-редактора и создайте новый файл через блокнот или другой текстовый редактор. Затем загрузите его на сервер в корневой каталог.
Запомните
Файл robots.txt помогает поисковым роботам индексировать сайт. Закрывайте сайт во время разработки, в остальное время - весь сайт или его часть должны быть открыты. Корректно работающий файл должен отдавать ответ 200.
Файл создается в обычном текстовом редакторе. Во многих CMS в административной панели предусмотрено создание файла. Следите, чтобы размер не превышал 32 КБ. Размещайте его в корневой директории сайта.
Заполняйте файл по правилам. Начинайте с кода “User-agent:”. Правила прописывайте блоками, отделяйте их пустой строкой. Соблюдайте принятый синтаксис.
Разрешайте или запрещайте индексацию всем краулерам или избранным. Для этого укажите название поискового робота или поставьте значок *, который означает «для всех».
Работайте с разными уровнями доступа: сайтом, страницей, папкой или типом файлов.
Включите в файл указание на главное зеркало с помощью постраничного 301 редиректа и на карту сайта с помощью директивы sitemap.
Для анализа robots.txt используйте инструменты для разработчиков. Это Яндекс.Вебмастер и Google Robots Testing Tools. Сначала подтвердите права на сайт, затем сделайте проверку. В Google сразу отредактируйте файл в веб-редакторе и уберите ошибки. Отредактированные файлы не сохраняются автоматически. Загружайте их на сервер вместо первоначального robots.txt. Через неделю проверьте, используют ли поисковики новую версию.
Материал подготовила Светлана Сирвида-Льорентэ.
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:
Исключения Яндекса
Стандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google , пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года . Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:
User-agent: *
Для конкретного бота:
User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:
user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site.ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Если нужно, чтобы все файлы.css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Host
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:
Host: site.ru
Пример 2:
Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:
Crawl-delay: 3
Пример 2:
Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Clean-param: author_id http://site.ru/articles/
Clean-param: author_id&sid http://site.ru/articles/
Clean-Param: utm_source&utm_medium&utm_campaign
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: *
Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
 Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
- Закройте от индексирования админку сайта
- Закройте от индексирования личный кабинет, авторизацию, регистрацию
- Закройте от индексирования корзину, формы заказа, данные по доставке и заказам
- Закройте от индексирования ajax, json-скрипты
- Закройте от индексирования папку cgi
- Закройте от индексирования плагины, темы оформления, js, css для всех роботов, кроме Яндекса и Google
- Закройте от индексирования функционал поиска
- Закройте от индексирования служебные разделы, которые не несут никакой ценности для сайта в поиске (ошибка 404, список авторов)
- Закройте от индексирования технические дубли страниц, а также страницы, на которых весь контент в том или ином виде продублирован с других страниц (календари, архивы, RSS)
- Закройте от индексирования страницы с параметрами фильтров, сортировки, сравнения
- Закройте от индексирования страницы с параметрами UTM-меток и сессий
- Проверьте, что проиндексировано Яндексом и Google с помощью параметра «site:» (в поисковой строке наберите «site:site.ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
- Укажите Sitemap и Host
- По необходимости пропишите Crawl-Delay и Clean-Param
- Проверьте корректность robots.txt через инструменты Google и Яндекса (описано ниже)
- Через 2 недели перепроверьте, появились ли в поисковой выдаче новые страницы, которые не должны индексироваться. В случае необходимости повторить выше перечисленные шаги.
Пример robots.txt
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif User-agent: Yandex Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif Clean-Param: utm_source&utm_medium&utm_campaign Crawl-Delay: 0.5 Sitemap: https://site.ru/sitemap.xml Host: https://site.ruКак добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
- В Яндекс.Вебмастере — на вкладке Инструменты>Анализ robots.txt
- В Google Search Console — на вкладке Сканирование>Инструмент проверки файла robots.txt
Типичные ошибки в robots.txt
 В конце статьи приведу несколько типичных ошибок файла robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
- robots.txt отсутствует
- в robots.txt сайт закрыт от индексирования (Disallow: /)
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий
- в файле указаны только директивы
Allow: *.css
Allow: *.js
Allow: *.png
Allow: *.jpg
Allow: *.gif
при этом файлы css, js, png, jpg, gif закрыты другими директивами в ряде директорий - директива Host прописана несколько раз
- в Host не указан протокол https
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта
P.S.
P.S.2
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
Карта сайта, значительно упрощает индексацию вашего блога. Карта сайта должна быть в обязательном порядке у каждого сайта и блога. Но также на каждом сайте и блоге должен быть файл robots. txt . Файл robots.txt содержит свод инструкций для поисковых роботов. Можно сказать, — правила поведения поисковых роботов на вашем блоге. А также в данном файле содержится путь к карте сайта вашего блога. И, по сути, при правильно составленном файле robots.txt поисковый робот не тратит драгоценное время на поиск карты сайта и индексацию не нужных файлов.
Что же из себя представляет файл robots.txt?
robots.txt – это текстовый файл, может быть создан в обычном «блокноте», расположенный в корне вашего блога, содержащий инструкции для поисковых роботов.
Эти инструкции ограничивают поисковых роботов от беспорядочной индексации всех файлов вашего бога, и нацеливают на индексацию именно тех страниц, которым следует попасть в поисковую выдачу.
С помощью данного файла, вы можете запретить индексацию файлов движка WordPress. Или, скажем, секретного раздела вашего блога. Вы можете указать путь к карте Вашего блога и главное зеркало вашего блога. Здесь я имею ввиду, ваше доменное имя с www и без www.
Индексация сайта с robots.txt и без
Данный скриншот, наглядно показывает, как файл robots.txt запрещает индексацию определённых папок на сайте. Без файла, роботу доступно всё на вашем сайте.
Основные директивы файла robots.txt
Для того чтобы разобраться с инструкциями, которые содержит файл robots.txt нужно разобраться с основными командами (директивы).
User-agent – данная команда обозначает доступ роботам к вашему сайту. Используя эту директиву можно создать инструкции индивидуально под каждого робота.
User-agent: Yandex – правила для робота Яндекс
User-agent: * — правила для всех роботов
Disallow и Allow – директивы запрета и разрешения. С помощью директивы Disallow запрещается индексация а с помощью Allow разрешается.
Пример запрета:
User-agent: *
Disallow: / — запрет ко всему сайта.
User-agent: Yandex
Disallow: /admin – запрет роботу Яндекса к страницам лежащим в папке admin.
Пример разрешения:
User-agent: *
Allow: /photo
Disallow: / — запрет ко всему сайту, кроме страниц находящихся в папке photo.
Примечание! директива Disallow: без параметра разрешает всё, а директива Allow: без параметра запрещает всё. И директивы Allow без Disallow не должно быть.
Sitemap – указывает путь к карте сайта в формате xml.
Sitemap: https://сайт/sitemap.xml.gz
Sitemap: https://сайт/sitemap.xml
Host – директива определяет главное зеркало Вашего блога. Считается, что данная директива прописывается только для роботов Яндекса. Данную директиву следует указывать в самом конце файла robots.txt.
User-agent: Yandex
Disallow: /wp-includes
Host: сайт
Примечание! адрес главного зеркала указывается без указания протокола передачи гипертекста (http://).
Как создать robots.txt
Теперь, когда мы познакомились с основными командами файла robots.txt можно приступать к созданию нашего файла. Для того чтобы создать свой файл robots.txt с вашими индивидуальными настройками, вам необходимо знать структуру вашего блога.
Мы рассмотрим создание стандартного (универсального) файла robots.txt для блога на WordPress. Вы всегда сможете дополнить его своими настройками.
Итак, приступаем. Нам понадобится обычный «блокнот», который есть в каждой операционной системе Windows. Или TextEdit в MacOS.
Открываем новый документ и вставляем в него вот эти команды:
User-agent: * Disallow: Sitemap: https://сайт/sitemap.xml.gz Sitemap: https://сайт/sitemap.xml User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /xmlrpc.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-content/languages Disallow: /category/*/* Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: /tag/ Disallow: /feed/ Disallow: */*/feed/*/ Disallow: */feed Disallow: */*/feed Disallow: /?feed= Disallow: /*?* Disallow: /?s= Host: сайт
Не забудьте заменить параметры директив Sitemap и Host на свои.
Важно! при написании команд, допускается лишь один пробел. Между директивой и параметром. Ни в коем случае не делайте пробелов после параметра или просто где попало.
Пример
:
Disallow:<пробел>/feed/
Данный пример файла robots.txt универсален и подходит под любой блог на WordPress с ЧПУ адресами url. О том что такое ЧПУ читайте . Если же Вы не настраивали ЧПУ, рекомендую из предложенного файла удалить Disallow: /*?* Disallow: /?s=

Загрузка файла robots.txt на сервер
Лучшим способом для такого рода манипуляций является FTP соединение. О том как настроить FTP соединение для TotolCommander читайте . Или же Вы можете использовать файловый менеджер на Вашем хостинге.
Я воспользуюсь FTP соединением на TotolCommander.
Сеть > Соединится с FTP сервером.

Выбрать нужное соединение и нажимаем кнопку «Соединиться».

Открываем корень блога и копируем наш файл robots.txt, нажав клавишу F5.

Копирование robots.txt на сервер
Вот теперь Ваш файл robots.txt будет исполнять надлежащие ему функции. Но я всё же рекомендую провести анализ robots.txt, чтобы удостоверится в отсутствии ошибок.
Для этого Вам потребуется войти в кабинет вебмастера Яндекс или Google. Рассмотрим примере Яндекс. Здесь можно провести анализ даже не подтверждая прав на сайт. Вам достаточно иметь почтовый ящик на Яндекс.
Открываем кабинет Яндекс.вебмастер.

На главной странице кабинета вебмастер, открываем ссылку «Проверить robots. txt» .

Для анализа потребуется ввести url адрес вашего блога и нажать кнопку «Загрузить robots. txt с сайта ». Как только файл будет загружен нажимаем кнопку «Проверить».

Отсутствие предупреждающих записей, свидетельствует о правильности создания файла robots.txt.

Ниже будет представлен результат. Где ясно и понятно какие материалы разрешены для показа поисковым роботам, а какие запрещены.

Результат анализа файла robots.txt
Здесь же вы можете вносить изменения в robots.txt и экспериментировать до получения нужного вам результата. Но помните, файл расположенный на вашем блоге при этом не меняется. Для этого вам потребуется полученный здесь результат скопировать в блокнот, сохранить как robots.txt и скопировать на Вас блог.
Кстати, если вам интересно как выглядит файл robots.txt на чьём-то блоге, вы может с лёгкостью его посмотреть. Для этого к адресу сайта нужно просто добавить /robots.txt
https://сайт/robots.txt
Вот теперь ваш robots.txt готов. И помните не откладывайте в долгий ящик создание файла robots.txt, от этого будет зависеть индексация вашего блога.
Если же вы хотите создать правильный robots.txt и при этом быть уверенным, что в индекс поисковых систем попадут только нужные страницы, то это можно сделать и автоматически с помощью плагина .
На этом у меня всё. Всем желаю успехов. Если будут вопросы или дополнения пишите в комментариях.
До скорой встречи.
С уважением, Максим Зайцев.
Подписывайтесь на новые статьи!
/ Просм: 21917
Здравствуйте уважаемые друзья ! Проверка robots.txt также важна, как и его правильное составление.
Проверка файла robots.txt в панели Yandex и Google Webmasters.
Проверка robots.txt, почему важно проверить?
Рано или поздно каждый уважающий себя автор сайта вспоминает про файл robots . Про этот файл, размещаемый в корне сайта, написано в интернете предостаточно. Почти у каждого вебмастера есть на сайте про актуальность и правильность составления его. Я же в этой статье напомню начинающим блоггерам как проверить его с помощью инструментов в панели вебмастера, предоставляемые Yandex и Google.
Для начала немного о нем. Файл Robots.txt (иногда ошибочно называемый robot.txt, в единственном числе, внимание английская буква s в конце обязательна) создается веб-мастерам, чтобы отметить или запретить те или иные файлы и папки веб-сайта, для поисковых пауков (а также других типов роботов). Т. е. те файлы, к которым робот поисковика не должен иметь доступ.
Проверка robots.txt является для автора сайта обязательным атрибутом при создании блога на WordPress и его дальнейшем продвижении. Многие вебмастера также обязательно просматривают страниц проекта. Анализ дает понять роботам правильный синтаксис, чтобы убедиться, в его действительном формате. Дело в том, что существует установленный Стандарт исключений для роботов. Будет не лишним узнать мнение самих поисковиков, читайте документацию, в ней поисковые системы подробно излагают свое видение насчет этого файла.
Все это будет не лишним, дабы впредь обезопасить свой сайт от ошибок при индексировании. Знаю примеры, когда из-за неправильного составленного файла, был дан сигнал запретить его видимость в сети. При дальнейшем его исправлении можно долго ждать изменения ситуации вокруг сайта.
Останавливаться на правильном составлении самого файла в этой статье не буду. Примеров в сети множество, можете зайти на блог любого популярного блоггера и приписать в конце его домена для проверки /robots.txt. Браузер покажет его вариант, который вы можете взять за основу. Однако у каждого бывают свои исключения, поэтому необходимо проверить именно для своего сайта на соответствие. Также описание и пример правильного текста для блога на WordPress находиться по адресу:
Sitemap: http: // ваш сайт/sitemap.xml
User-agent: Googlebot-Image
# Google AdSense
User-agent: Mediapartners-Google*
User-agent: duggmirror
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/cache/
Disallow: /wp-content/themes/
Disallow: /trackback/
Disallow: /feed/
Disallow: /comments/
Disallow: /category/*/*
Disallow: */trackback/
Disallow: */feed/
Disallow: */comments/
Allow: /wp-content/uploads/
Существуют некоторые различия в составлении и дальнейшей проверки файла robots.txt для основных поисковых систем Рунета. Ниже приведу примеры, как проверить в панели Яндекс Вебмастер и Google.
После того как вы составили файл и закинули его в корень своего сайта по FTP необходимо провести проверку его на соответствие к примеру поисковой системе Яндекс. Тем самым мы узнаем, не закрыли ли мы случайно те страницы, благодаря которым к вам придут посетители.
Проверка robots.txt в панели Yandex Webmaster
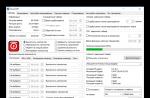
У вас должен быть аккаунт в панели Яндекс Вебмастер. Зайдя в инструменты и указав свой сайт, справа будет перечень доступных возможностей. Переходим на вкладку «Проверить robots.txt»
Указываем свой домен и жмем «Загрузить robots.txt с сайта». Если у вас составлен файл, в котором указано отдельно для каждой поисковой системы, то необходимо выбрать строки для Яндекс и скопировать их в поле ниже. Напоминаю, директива Host: актуальна для Янд., поэтому не забудьте внести в поле для проверки. Осталось сделать проверку robots.txt. Кнопка справа.

Буквально сразу увидите анализ от Яндекс на соответствие вашего robots.txt. Ниже будет указаны строки, которые Янд. принял к рассмотрению. И смотрим результаты проверки. Слева Url указаны директивы. Справа напротив сам результат. Как видно на скриншоте, правильно будет увидеть красным цветом надпись – запрещен правилом и указано само правило. Если вы указали директиву для индексации, то увидим зеленым – разрешен.
После проверки robots.txt, вы сможете подкорректировать свой файл. Также рекомендую проверить страницы сайта. Вставляем url адрес отдельной записи в поле /Список URL/. И на выходе получаем результат – разрешен. Так мы сможет отдельно проверить запреты на архивы, рубрики и далее.
Не забываем подписываться, в следующей статье планирую показать, как бесплатно пройти регистрацию в каталог Mail.ru. Не пропустите, .
Как проверить в Yandex Webmasters.
Проверить robots.txt в панели Google Webmasters
Заходим в свой аккаунт и ищем слева /Состояние/ – /Заблокированные URL/Здесь увидим его наличие и возможность отредактировать. При необходимости проверки всего сайта на соответствие указываем в поле ниже адрес главной страницы. Имеется возможность проверить, как видят разные роботы Google ваш сайт с учетом проверки файла robots.txt

Кроме основного бота Google выбираем и робота специализирующегося на разных видах контента (2). Скриншот ниже.
- Googlebot
- Googlebot-Image
- Googlebot-Mobile
- Mediapartners-Google – показатели для AdSense
- AdsBot-Google – проверка качества целевой стр.
Показатели для других роботов Гугл я не нашел:
- Googlebot Video
- Googlebot-News

По аналогии с проверкой файла роботс.тхт в панели Яндекс, здесь также есть возможность проанализировать отдельную страницу сайта. После проверки вы увидите результат отдельно для каждого поискового бота.
При условии, что результаты проверки вас не устроили, вам остается дальше продолжить редактировать. И в дальнейшем проверка.
Анализ robots.txt онлайн
Кроме этих возможностей, вы также можете сделать анализ файла robots.txt с помощью онлайн сервисов. Те которые я находил в основном англоязычные. Мне понравился этот сервис. После анализа будут даны рекомендации по его исправлению.
tool.motoricerca.info/robots-checker.phtml
На этом все. Надеюсь, проверка файла robots.txt глазами Яндекс и Google вас не расстроила? Если же увидели не соответствие вашим желаниям, то всегда можно отредактировать и затем сделать повторный анализ. Спасибо за ваш твит в Twitter и лайк в Facebook!